Title: 逻辑回归优化技巧总结(全) · Issue #34 · aialgorithm/Blog · GitHub
Open Graph Title: 逻辑回归优化技巧总结(全) · Issue #34 · aialgorithm/Blog
X Title: 逻辑回归优化技巧总结(全) · Issue #34 · aialgorithm/Blog
Description: 逻辑回归由于其简单高效、易于解释,是工业应用最为广泛的模型之一,比如用于金融风控领域的评分卡、互联网的推荐系统。上文总结了逻辑回归的原理及其实现【全面解析并实现逻辑回归(Python)】。 本文从实际应用出发,以数据特征、优化算法、模型优化等方面,全面地归纳了逻辑回归(LR)优化技巧。 一、LR的特征生成 逻辑回归是简单的广义线性模型,模型的拟合能力很有限,无法学习到特征间交互的非线性信息:一个经典的示例是LR无法正确分类非线性的XOR数据,而通过引入非线性的特征(特征...
Open Graph Description: 逻辑回归由于其简单高效、易于解释,是工业应用最为广泛的模型之一,比如用于金融风控领域的评分卡、互联网的推荐系统。上文总结了逻辑回归的原理及其实现【全面解析并实现逻辑回归(Python)】。 本文从实际应用出发,以数据特征、优化算法、模型优化等方面,全面地归纳了逻辑回归(LR)优化技巧。 一、LR的特征生成 逻辑回归是简单的广义线性模型,模型的拟合能力很有限,无法学习到特征间交互的非线性信息:...
X Description: 逻辑回归由于其简单高效、易于解释,是工业应用最为广泛的模型之一,比如用于金融风控领域的评分卡、互联网的推荐系统。上文总结了逻辑回归的原理及其实现【全面解析并实现逻辑回归(Python)】。 本文从实际应用出发,以数据特征、优化算法、模型优化等方面,全面地归纳了逻辑回归(LR)优化技巧。 一、LR的特征生成 逻辑回归是简单的广义线性模型,模型的拟合能力很有限,无法学习到特征间交互的非线性信息:...
Opengraph URL: https://github.com/aialgorithm/Blog/issues/34
X: @github
Domain: github.com
{"@context":"https://schema.org","@type":"DiscussionForumPosting","headline":"逻辑回归优化技巧总结(全)","articleBody":"\u003e逻辑回归由于其简单高效、易于解释,是工业应用最为广泛的模型之一,比如用于金融风控领域的评分卡、互联网的推荐系统。上文总结了逻辑回归的原理及其实现[【全面解析并实现逻辑回归(Python)】](https://mp.weixin.qq.com/s/w824fCjZ8OHr5jawlhOpaQ)。\r\n\u003e本文从实际应用出发,以数据特征、优化算法、模型优化等方面,全面地归纳了逻辑回归(LR)优化技巧。\r\n\r\n\r\n### 一、LR的特征生成\r\n逻辑回归是简单的广义线性模型,模型的拟合能力很有限,无法学习到特征间交互的非线性信息:一个经典的示例是LR无法正确分类非线性的XOR数据,而通过引入非线性的特征(特征生成),可在更高维特征空间实现XOR线性可分。\r\n\r\n\r\n\r\n```\r\n# 生成xor数据\r\nimport pandas as pd \r\nxor_dataset = pd.DataFrame([[1,1,0],[1,0,1],[0,1,1],[0,0,0]],columns=['x0','x1','label'])\r\nx,y = xor_dataset[['x0','x1']], xor_dataset['label']\r\nxor_dataset.head()\r\n\r\n# keras实现逻辑回归\r\nfrom keras.layers import *\r\nfrom keras.models import Sequential, Model\r\nfrom tensorflow import random\r\nnp.random.seed(5) # 固定随机种子\r\nrandom.set_seed(5)\r\nmodel = Sequential()\r\nmodel.add(Dense(1, input_dim=3, activation='sigmoid'))\r\nmodel.summary()\r\nmodel.compile(optimizer='adam', loss='binary_crossentropy')\r\nxor_dataset['x2'] = xor_dataset['x0'] * xor_dataset['x1'] # 加入非线性特征\r\nx,y = xor_dataset[['x0','x1','x2']], xor_dataset['label']\r\nmodel.fit(x, y, epochs=10000,verbose=False)\r\nprint(\"正确标签:\",y.values)\r\nprint(\"模型预测:\",model.predict(x).round())\r\n# 正确标签: [0 1 1 0] 模型预测: [0 1 1 0]\r\n```\r\n业界常说“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”。由于LR是简单模型,其特征质量基本决定了其最终效果(也就是简单模型要比较折腾特征工程)。\r\n\r\nLR常用特征生成(提取)的方式主要有3种:\r\n\r\n- 人工结合业务衍生特征:人工特征的好处是加工出的特征比较有业务解释性,更贴近实际业务。缺点是很依赖业务知识,耗时。\r\n\r\n- 特征衍生工具:如通过featuretools暴力衍生特征(相关代码可以参考[【特征生成方法】](https://mp.weixin.qq.com/s?__biz=MzI4MDE1NjExMQ==\u0026mid=2247484083\u0026idx=1\u0026sn=851e06d56920ce2c0f6ce0a2ff4af2c7\u0026scene=19#wechat_redirect)),ft生成特征的常用方法有聚合(求平均值、最大值最小值)、转换(特征间加减乘除)的方式。暴力衍生特征速度较快。缺点是更占用计算资源,容易产生一些噪音,而且不太适合要求特征解释性的场景。(需要注意的:简单地加减做线性加工特征的方法对于LR是没必要的,模型可以自己表达)\r\n\r\n- 基于模型的方法: \r\n\r\n如POLY2、引入隐向量的因子分解机(FM)可以看做是LR的基础上,对所有特征进行了两两交叉,生成非线性的特征组合。\r\n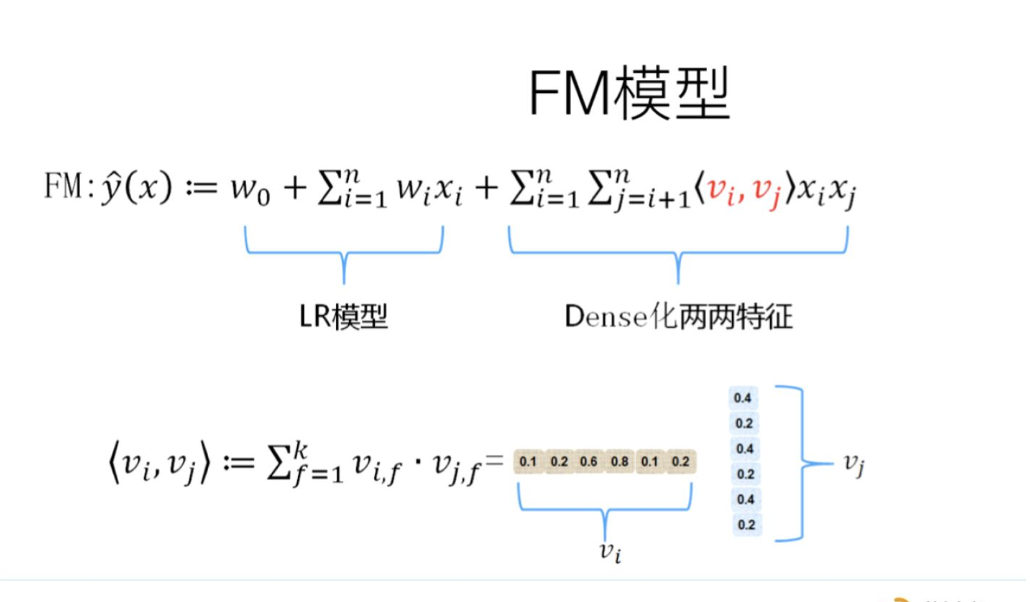\r\n但FM等方法只能够做二阶的特征交叉,更为有效的是,利用**GBDT自动进行筛选特征并生成特征组合**。也就是提取GBDT子树的特征划分及组合路径作为新的特征,再把该特征向量当作LR模型输入,也就是推荐系统经典的GBDT +LR方法。(需要注意的,GBDT子树深度太深的化,特征组合层次比较高,极大提高LR模型拟合能力的同时,也容易引入一些噪声,导致模型过拟合)\r\n\r\n如下GBDT+LR的代码实现(基于癌细胞数据集),提取GBDT特征,并与原特征拼接:\r\n\r\n训练并评估模型有着较优的分类效果:\r\n\r\n\r\n```\r\n## GBDT +LR ,公众号阅读原文,可访问Github源码\r\nfrom sklearn.preprocessing import OneHotEncoder\r\nfrom sklearn.ensemble import GradientBoostingClassifier\r\n\r\ngbdt = GradientBoostingClassifier(n_estimators=50, random_state=10, subsample=0.8, max_depth=6,\r\n min_samples_split=20)\r\ngbdt.fit(x_train, y_train) # GBDT 训练集训练\r\n\r\ntrain_new_feature = gbdt.apply(x) # 返回数据在训练好的模型里每棵树中所处的叶子节点的位置\r\nprint(train_new_feature.shape)\r\ntrain_new_feature = train_new_feature.reshape(-1, 50)\r\ndisplay(train_new_feature)\r\nprint(train_new_feature.shape)\r\n\r\nenc = OneHotEncoder()\r\nenc.fit(train_new_feature)\r\ntrain_new_feature2 = np.array(enc.transform(train_new_feature).toarray()) # onehot表示\r\n\r\nprint(train_new_feature2.shape)\r\ntrain_new_feature2\r\n```\r\n\r\n\r\n\r\n\r\n### 二、特征离散化及编码表示\r\nLR对于连续性的数值特征的输入,通常需要对特征做下max-min归一化(x =x-min/(max-min),转换输出为在 0-1之间的数,这样可以加速模型计算及训练收敛。但其实在工业界,很少直接将连续值作为逻辑回归模型的特征输入,而是先将连续特征离散化(常用的有等宽、等频、卡方分箱、决策树分箱等方式,而分箱的差异也直接影响着模型效果),然后做(Onehot、WOE)编码再输入模型。\r\n\r\n之所以这样做,我们回到模型的原理,逻辑回归是广义线性模型,模型无非就是对特征线性的加权求和,在通过sigmoid归一化为概率。这样的特征表达是很有限的。以年龄这个特征在识别是否存款为例。在lr中,年龄作为一个特征对应一个权重w控制,输出值 = sigmoid(...+age * w+..),可见年龄数值大小在模型参数w的作用下只能呈线性表达。\r\n\r\n但是对于年龄这个特征来说,不同的年龄值,对模型预测是否会存款,应该不是线性关系,比如0-18岁可能对于存款是负相关,19-55对于存款可能就正相关。这意味着不同的特征值,需要不同模型参数来更好地表达。也就是通过对特征进行离散化,比如年龄可以离散化以及哑编码(onehot)转换成4个特征(if_age\u003c18, if_18\u003cage\u003c30,if_30\u003cage\u003c55,if_55\u003cage )输入lr模型,就可以用4个模型参数分别控制这4个离散特征的表达:sigmoid(...+age1 * w1+age2 * w2..),**这明显可以增加模型的非线性表达,提高了拟合能力**。\r\n\r\n在风控领域,特征离散后更常用特征表示(编码)还不是onehot,而是WOE编码。\r\n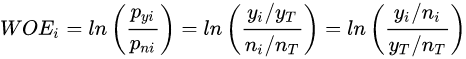\r\nwoe编码是通过对当前分箱中正负样本的比值Pyi与所有样本中正负样本比值Pni的差异(如上式),计算出各个分箱的woe值,作为该分箱的数值表示。\r\n\r\n经过分箱、woe编码后的特征很像是决策树的决策过程,以年龄特征为例: if age \u003e18 and age\u003c22 then return - 0.57(年龄数值转为对应WOE值); if age \u003e44 then return 1.66;...;将这样的分箱及编码(对应树的特征划分、叶子节点值)输入LR,很类似于决策树与LR的模型融合,而提高了模型的非线性表达。\r\n\r\n**总结下离散化编码的优点:**\r\n\r\n- 逻辑回归的拟合能力有限,当变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型拟合能力的同时,也有更好的解释性。而且离散化后可以方便地进行特征交叉,由M+N个变量变为M*N个变量,可以进一步提升表达能力。\r\n- 离散化后的特征对异常数据有较强的鲁棒性:比如一个特征是年龄\u003e44是1,否则0。如果特征没有离散化,一个异常数据“年龄200岁”输入会给模型造成很大的干扰,而将其离散后归到相应的分箱影响就有限。\r\n- 离散化后模型会更稳定,且不容易受到噪声影响,减少过拟合风险:比如对用户年龄离散化,18-22作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同样本。\r\n\r\n### 三、特征选择\r\n特征选择用于筛选出显著特征、摒弃非显著特征。可以降低运算开销,减少干扰噪声,降低过拟合风险,提升模型效果。对于逻辑回归常用如下三种选择方法:\r\n\r\n过滤法:利用缺失率、单值率、方差、pearson相关系数、VIF、IV值、PSI、P值等指标对特征进行筛选;(相关介绍及代码可见:[【特征选择】](https://mp.weixin.qq.com/s?__biz=MzI4MDE1NjExMQ==\u0026mid=2247483996\u0026idx=1\u0026sn=1659cedcc0268f2bee803e96eceabab5\u0026scene=19#wechat_redirect))\r\n\r\n嵌入法:使用带L1正则项的逻辑回归,有特征选择(稀疏解)的效果;\r\n\r\n包装法:使用逐步逻辑回归,双向搜索选择特征。\r\n\r\n\r\n其中,过滤法提到的VIF是共线性指标,其原理是分别尝试以各个特征作为标签,用其他特征去学习拟合,得到线性回归模型拟合效果的R^2值,算出各个特征的VIF。特征的VIF为1,即无法用其他特征拟合出当前特征,特征之间完全没有共线性(工程上常用VIF\u003c10作为阈值)\r\n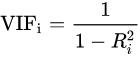\r\n共线性对于广义线性模型主要影响了特征实际的显著性及权重参数(比如,该特征业务上应该正相关,而权重值却是负的),也会消弱模型解释性以及模型训练的稳定性。\r\n\r\n\r\n\r\n### 四、模型层面的优化\r\n\r\n#### 4.1 截距项\r\n通过设置截距项(偏置项)b可以提高逻辑回归的拟合能力。截距项可以简单理解为模型多了一个参数b(也可以看作是新增一列常数项特征对应的参数w0),这样的模型复杂度更高,有更好的拟合效果。\r\n\r\n如果没有截距项b呢?我们知道逻辑回归的决策边界是线性的(即决策边界为W * X + b),如果没有截距项(即W * X),决策边界就限制在必须是通过坐标圆点的,这样的限制很有可能导致模型收敛慢、精度差,拟合不好数据,即容易欠拟合。\r\n\r\n\r\n\r\n#### 4.2 正则化策略\r\n通过设定正则项可以减少模型的过拟合风险,常用的正则策略有L1,L2正则化:\r\n- L2 参数正则化 (也称为岭回归、Tikhonov 正则) 通常被称为权重衰减 (weight decay),是通过向⽬标函数添加⼀个正则项 Ω(θ) ,使权重更加接近原点,模型更为简单。从贝叶斯角度,L2的约束项可以视为模型参数引入先验的高斯分布约束(参见《Lazy Sparse Stochastic Gradient Descent for Regularized》 )。如下为目标函数J再加上L2正则式:\r\n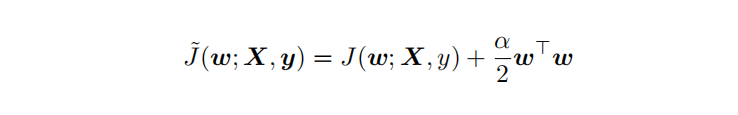\r\n对带L2目标函数的模型参数更新权重,ϵ学习率:\r\n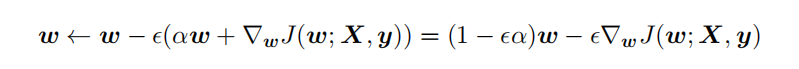\r\n\r\n从上式可以看出,加⼊权重衰减后会导致学习规则的修改,即在每步执⾏梯度更新前先收缩权重 (乘以 1 − ϵα ),有权重衰减的效果。\r\n\r\n\r\n- L1 正则化(Lasso回归)是通过向⽬标函数添加⼀个参数惩罚项 Ω(θ),为各个参数的绝对值之和。从贝叶斯角度,L1的约束项也可以视为模型参数引入拉普拉斯分布约束。如下为目标函数J再加上L1正则式:\r\n\r\n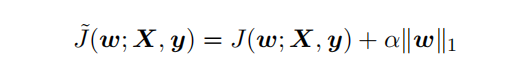\r\n\r\n对带L1目标函数的模型参数更新权重(其中 sgn(x) 为符号函数,取参数的正负号):\r\n\r\n可见,在-αsgn(w)项的作用下, w各元素每步更新后的权重向量都会平稳地向0靠拢,w的部分元素容易为0,造成稀疏性。\r\n\r\n\r\n**总结下L1,L2正则项:**\r\n\r\nL1,L2都是限制解空间,减少模型容量的方法,以到达减少过拟合的效果。\r\nL2范式约束具有产生平滑解的效果,没有稀疏解的能力,即参数并不会出现很多零。假设我们的决策结果与两个特征有关,L2正则倾向于综合两者的影响,给影响大的特征赋予高的权重;而L1正则倾向于选择影响较大的参数,而尽可能舍弃掉影响较小的那个(有稀疏解效果)。在实际应用中 L2正则表现往往会优于 L1正则,但 L1正则会压缩模型,降低计算量。\r\n\r\n\r\n#### 4.3 多分类任务\r\n当逻辑回归应用于二分类任务时有两种主要思路,\r\n\r\n- 沿用Sigmoid激活函数的二分类思路,把多分类变成多个二分类组合有两种实现方式:OVR(one-vs-rest)的思想就是用一个类别去与其他汇总的类别进行二分类, 进行多次这样的分类, 选择概率值最大的那个类别;\r\nOVO(One vs One)每个分类器只挑两个类别做二分类, 得出属于哪一类,最后把所有分类器的结果放在一起, 选择最多的那个类别,如下图:\r\n\r\n\r\n\r\n- 另外一种,将Sigmoid激活函数换成softmax函数,相应的模型也可以叫做多元逻辑回归(Multinomial Logistic Regression),即可适用于多分类的场景。softmax函数简单来说就是将多个神经元(神经元数目为类别数)输出的结果映射到各输出的占比(范围0~1, 占比可以理解成概率),我们通过选择概率最大输出类别作为预测类别。\r\n\r\n\r\n如下softmax函数及对应的多分类目标函数:\r\n\r\n softmax回归中,一般是假设多个类别是互斥的,样本在softmax中的概率公式中计算后得到的是样本属于各个类别的值,各个类别的概率之和一定为1,而采用logistic回归OVR进行多分类时,得到的是值是样本相对于其余类别而言属于该类别的概率,一个样本在多个分类器上计算后得到的结果不一定为1。因而当分类的目标类别是互斥时(例如分辨猫、猪、狗图片),常采用softmax回归进行预测,而分类目标类别不是很互斥时(例如分辨流行音乐、摇滚、华语),可以采用逻辑回归建立多个二分类器(也可考虑下多标签分类)。\r\n\r\n\r\n#### 4.4 学习目标\r\n逻辑回归使用最小化交叉熵损失作为目标函数,\r\n\r\n\r\n为什么不能用MSE均方误差?\r\n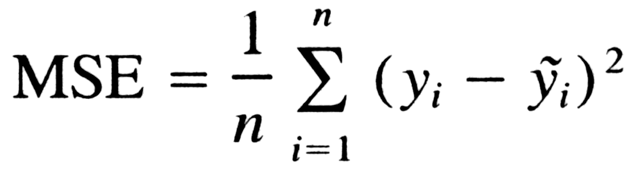\r\n简单来说,有以下几点:\r\n- MSE 损失函数的背景假设是数据误差遵循高斯分布,而二分类问题并不符合这个假设 。\r\n- 交叉熵的损失函数只关注真实类别对应预测误差的差异。而MSE无差别地关注全部类别上预测概率和真实类别的误差,除了增大正确的分类,还会让错误的分类数值变得平均。\r\n- MSE 函数对于sigmoid二分类问题来说是非凸的,且求导的时候都会有对sigmoid的求导连乘运算,导数值可能很小而导致收敛变慢,不能保证将损失函数极小化。\r\n但mse也不是完全不能用于分类,对于分类软标签就可以考虑MSE。\r\n\r\n#### 4.5 优化算法\r\n最大似然下的逻辑回归没有解析解,我们常用梯度下降之类的算法迭代优化得到局部较优的参数解。\r\n\r\n如果是Keras等神经网络库建模,梯度下降算法类有SGD、Momentum、Adam等优化算法可选。对于大多数任务而言,通常可以直接先试下Adam,然后可以继续在具体任务上验证不同优化算法效果。\r\n\r\n如果用的是scikitl-learn库建模,优化算法主要有liblinear(坐标下降)、newton-cg(拟牛顿法), lbfgs(拟牛顿法)和sag(随机平均梯度下降)。liblinear支持L1和L2,只支持OvR做多分类;“lbfgs”, “sag” “newton-cg”只支持L2,支持OvR和MvM做多分类;当数据量特别大,优先sag!\r\n\r\n\r\n#### 4.6 模型评估 \r\n- 模型阈值(cutoff点)\r\n当评估指标是分类Precision、Recall等指标时,可以通过优化模型阈值(默认0.5)提高分类效果。常用可以根据不同划分阈值下的presion与recall曲线(P-R曲线),做出权衡,选择合适的模型阈值。\r\n\r\n\r\n#### 4.7 可解释性\r\n逻辑回归模型 很大的优势就是可解释性,上节提到通过离散化编码(如Onehot)可以提高拟合效果及解释性,如下特征离散后Onehot编码:\r\n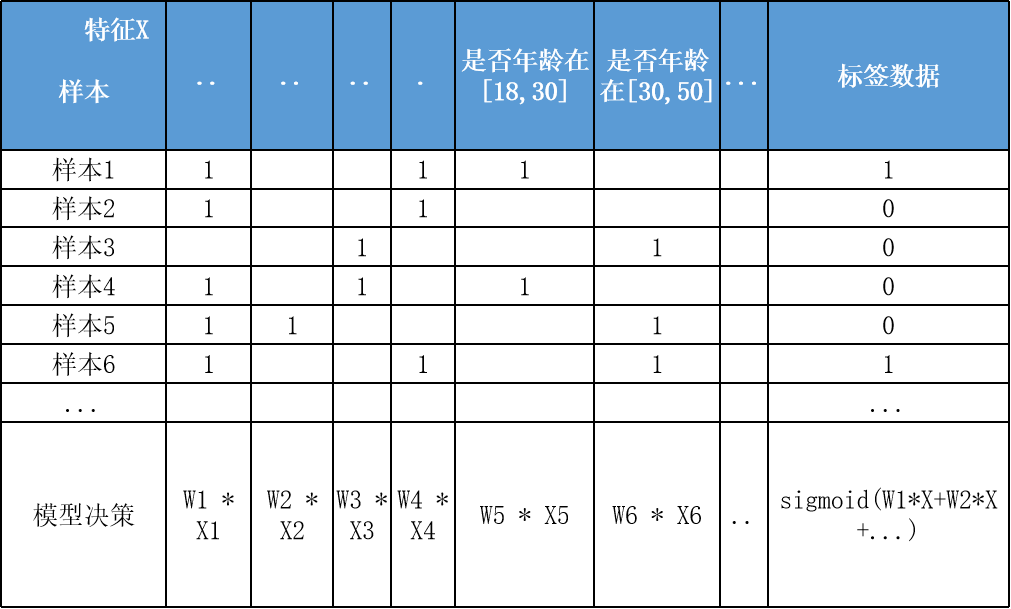\r\n决策过程也就是对特征分箱Xn及其模型权重Wn的加权求和,而通过模型权重值的大小就可以知道各特征对于决策的实际影响程度,比如特征\"年龄在[18,30]\"对应学到权重值为-0.8,也就是负相关。\r\n","author":{"url":"https://github.com/aialgorithm","@type":"Person","name":"aialgorithm"},"datePublished":"2021-11-25T12:08:02.000Z","interactionStatistic":{"@type":"InteractionCounter","interactionType":"https://schema.org/CommentAction","userInteractionCount":0},"url":"https://github.com/34/Blog/issues/34"}| route-pattern | /_view_fragments/issues/show/:user_id/:repository/:id/issue_layout(.:format) |
| route-controller | voltron_issues_fragments |
| route-action | issue_layout |
| fetch-nonce | v2:742c126f-5c38-2bfe-da6d-39d846cf53c3 |
| current-catalog-service-hash | 81bb79d38c15960b92d99bca9288a9108c7a47b18f2423d0f6438c5b7bcd2114 |
| request-id | 810C:106A75:856B2A:BC2819:696A1646 |
| html-safe-nonce | 7197d059707d495b79ded34f6d21bd91a10ee1f425778e4dc9e5745d57c1574b |
| visitor-payload | eyJyZWZlcnJlciI6IiIsInJlcXVlc3RfaWQiOiI4MTBDOjEwNkE3NTo4NTZCMkE6QkMyODE5OjY5NkExNjQ2IiwidmlzaXRvcl9pZCI6Ijc2OTA1OTI0ODUyMTMwODMyMDciLCJyZWdpb25fZWRnZSI6ImlhZCIsInJlZ2lvbl9yZW5kZXIiOiJpYWQifQ== |
| visitor-hmac | 81faee2d31e25efbffad03df6175c8163e892ae2e91fdb38dfeef13ea1ade0bf |
| hovercard-subject-tag | issue:1063509330 |
| github-keyboard-shortcuts | repository,issues,copilot |
| google-site-verification | Apib7-x98H0j5cPqHWwSMm6dNU4GmODRoqxLiDzdx9I |
| octolytics-url | https://collector.github.com/github/collect |
| analytics-location | / |
| fb:app_id | 1401488693436528 |
| apple-itunes-app | app-id=1477376905, app-argument=https://github.com/_view_fragments/issues/show/aialgorithm/Blog/34/issue_layout |
| twitter:image | https://opengraph.githubassets.com/441aab51867cd62e81f23e12cd3b756294ee338fe745cc9b22713502407abc91/aialgorithm/Blog/issues/34 |
| twitter:card | summary_large_image |
| og:image | https://opengraph.githubassets.com/441aab51867cd62e81f23e12cd3b756294ee338fe745cc9b22713502407abc91/aialgorithm/Blog/issues/34 |
| og:image:alt | 逻辑回归由于其简单高效、易于解释,是工业应用最为广泛的模型之一,比如用于金融风控领域的评分卡、互联网的推荐系统。上文总结了逻辑回归的原理及其实现【全面解析并实现逻辑回归(Python)】。 本文从实际应用出发,以数据特征、优化算法、模型优化等方面,全面地归纳了逻辑回归(LR)优化技巧。 一、LR的特征生成 逻辑回归是简单的广义线性模型,模型的拟合能力很有限,无法学习到特征间交互的非线性信息:... |
| og:image:width | 1200 |
| og:image:height | 600 |
| og:site_name | GitHub |
| og:type | object |
| og:author:username | aialgorithm |
| hostname | github.com |
| expected-hostname | github.com |
| None | 34a52bd10bd674f68e5c1b6b74413b79bf2ca20c551055ace3f7cdd112803923 |
| turbo-cache-control | no-preview |
| go-import | github.com/aialgorithm/Blog git https://github.com/aialgorithm/Blog.git |
| octolytics-dimension-user_id | 33707637 |
| octolytics-dimension-user_login | aialgorithm |
| octolytics-dimension-repository_id | 147093233 |
| octolytics-dimension-repository_nwo | aialgorithm/Blog |
| octolytics-dimension-repository_public | true |
| octolytics-dimension-repository_is_fork | false |
| octolytics-dimension-repository_network_root_id | 147093233 |
| octolytics-dimension-repository_network_root_nwo | aialgorithm/Blog |
| turbo-body-classes | logged-out env-production page-responsive |
| disable-turbo | false |
| browser-stats-url | https://api.github.com/_private/browser/stats |
| browser-errors-url | https://api.github.com/_private/browser/errors |
| release | e8bd37502700f365b18a4d39acf7cb7947e11b1a |
| ui-target | full |
| theme-color | #1e2327 |
| color-scheme | light dark |
Links:
Viewport: width=device-width