Title: 一文搞定深度学习建模预测全流程 · Issue #31 · aialgorithm/Blog · GitHub
Open Graph Title: 一文搞定深度学习建模预测全流程 · Issue #31 · aialgorithm/Blog
X Title: 一文搞定深度学习建模预测全流程 · Issue #31 · aialgorithm/Blog
Description: 本文详细地梳理及实现了深度学习模型构建及预测的全流程,代码示例基于python及神经网络库keras,通过设计一个深度神经网络模型做波士顿房价预测。主要依赖的Python库有:keras、scikit-learn、pandas、tensorflow(建议可以安装下anaconda包,自带有常用的python库) 一、基础介绍 机器学习 机器学习的核心是通过模型从数据中学习并利用经验去决策。进一步的,机器学习一般可以概括为:从数据出发,选择某种模型,通过优化算法更新模型的...
Open Graph Description: 本文详细地梳理及实现了深度学习模型构建及预测的全流程,代码示例基于python及神经网络库keras,通过设计一个深度神经网络模型做波士顿房价预测。主要依赖的Python库有:keras、scikit-learn、pandas、tensorflow(建议可以安装下anaconda包,自带有常用的python库) 一、基础介绍 机器学习 机器学习的核心是通过模型从数据中学习并利用经验去决策。进...
X Description: 本文详细地梳理及实现了深度学习模型构建及预测的全流程,代码示例基于python及神经网络库keras,通过设计一个深度神经网络模型做波士顿房价预测。主要依赖的Python库有:keras、scikit-learn、pandas、tensorflow(建议可以安装下anaconda包,自带有常用的python库) 一、基础介绍 机器学习 机器学习的核心是通过模型从数据中学习并利用经验去决策。进...
Opengraph URL: https://github.com/aialgorithm/Blog/issues/31
X: @github
Domain: github.com
{"@context":"https://schema.org","@type":"DiscussionForumPosting","headline":"一文搞定深度学习建模预测全流程","articleBody":"本文详细地梳理及实现了深度学习模型构建及预测的全流程,代码示例基于python及神经网络库keras,通过设计一个深度神经网络模型做波士顿房价预测。主要依赖的Python库有:keras、scikit-learn、pandas、tensorflow(建议可以安装下anaconda包,自带有常用的python库)\r\n\r\n## 一、基础介绍\r\n\r\n\r\n- 机器学习\r\n\r\n机器学习的核心是通过模型从数据中学习并利用经验去决策。进一步的,机器学习一般可以概括为:从数据出发,选择某种模型,通过优化算法更新模型的参数值,使任务的指标表现变好(学习目标),最终学习到“好”的模型,并运用模型对数据做预测以完成任务。由此可见,机器学习方法有四个要素:**数据、模型、学习目标、优化算法**。具体可见系列文章:[一篇白话机器学习概念](https://mp.weixin.qq.com/s/wS40NkZwkPnJK-RciYLk-A)\r\n\r\n- 深度学习\r\n\r\n深度学习是机器学习的一个分支,它是使用多个隐藏层**神经网络模型**,通过大量的向量计算,学习到数据内在规律的高阶表示特征,并利用这些特征决策的过程。\r\n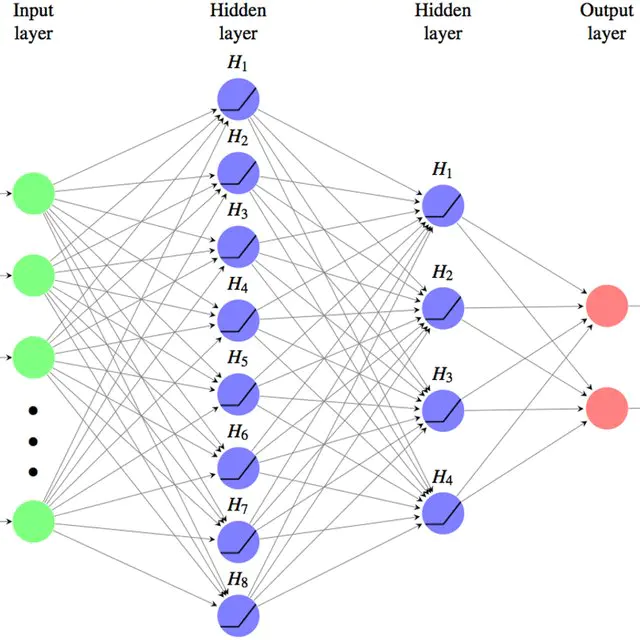\r\n\r\n- keras简介\r\n\r\n本文基于keras搭建神经网络模型去预测,keras是python上常用的神经网络库。相比于tensorflow、Pytorch等库,它对初学者很友好,开发周期较快。下图为keras要点知识的速查表(pdf原版到公众号阅读原文后可见):\r\n\r\n\r\n## 二、建模流程\r\n深度学习的建模预测流程,与传统机器学习整体是相同的,主要区别在于深度学习是端对端学习,可以自动提取高层次特征,大大减少了传统机器学习依赖的特征工程。如下详细梳理流程的各个节点并附相应代码:\r\n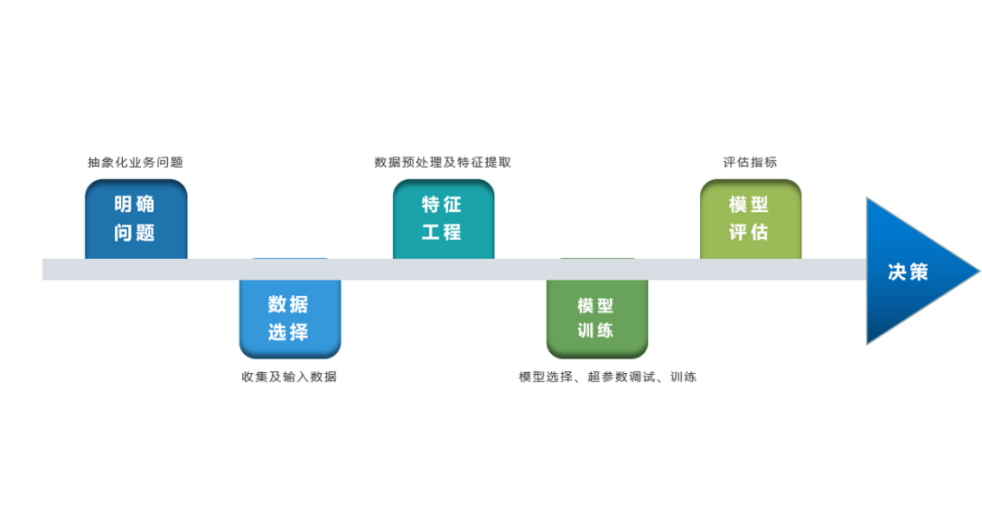\r\n\r\n### 2.1 明确问题及数据选择\r\n#### 2.1.1 明确问题\r\n\r\n深度学习的建模预测,首先需要明确问题,即抽象为机器 / 深度学习的预测问题:需要学习什么样的数据作为输入,目标是得到什么样的模型做决策作为输出。\r\n\r\n以预测房价为例,我们需要输入:和房价有关的数据信息为特征x,对应的房价为y作为监督信息。再通过神经网络模型学习特征x到房价y内在的映射关系。通过学习好的模型输入需要预测数据的特征x,输出模型预测Y。对于一个良好的模型,它预测房价Y应该和实际y很接近。\r\n\r\n\r\n#### 2.1.2 数据选择\r\n\r\n深度学习是端对端学习,学习过程中会提取到高层次抽象的特征,大大弱化特征工程的依赖,正因为如此,数据选择也显得格外重要,其决定了模型效果的上限。如果数据质量差,预测的结果自然也是很差的——业界一句名言“garbage in garbage out”。\r\n\r\n\r\n\r\n数据选择是准备机器 / 深度学习原料的关键,需要关注的是:\r\n\r\n①数据样本规模:对于深度学习等复杂模型,通常样本量越多越好。如《[Revisiting Unreasonable Effectiveness of Data in Deep Learning Era](https://arxiv.org/abs/1707.02968) 》等研究,一定规模下,深度学习性能会随着数据量的增加而增加。\r\n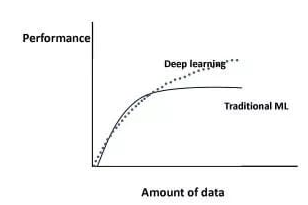\r\n然而工程实践中,受限于硬件支持、标注标签成本等原因,样本的数据量通常是比较有限的,这也是机器学习的重难点。对于模型所需最少的样本量,其实没有固定准则,需要要结合实际样本特征、任务复杂度等具体情况(经验上,对于分类任务,每个类别要上千的样本数)。当样本数据量较少以及样本不均衡情况,深度学习常用到数据增强的方法,具体可见系列文章:[《数据增强方法的归纳》](https://mp.weixin.qq.com/s?__biz=MzI4MDE1NjExMQ==\u0026mid=2247484169\u0026idx=1\u0026sn=54d58e40b31ee34c7fe3c44c096a4221\u0026chksm=ebbd81a9dcca08bf6eb508a8e71ce36fbeb1fc75f6bb55cd646b74d509d0c2cd83402d21cf29\u0026cur_album_id=1986073923821551618\u0026scene=189#rd)\r\n\r\n\r\n② 数据的代表性:数据质量差、无代表性,会导致模型拟合效果差。需要明确与任务相关的数据表范围,避免缺失代表性数据或引入大量无关数据作为噪音。\r\n\r\n③ 数据时间范围:对于监督学习的特征变量x及标签y,如与时间先后有关,则需要划定好数据时间窗口,否则可能会导致常见的数据泄漏问题,即存在了特征与标签因果颠倒的情况。\r\n\r\n\r\n以预测房价任务为例,对数据选择进行说明:\r\n- 收集房价相关的数据信息(特征维度)和对应房价(标签),以及尽量多的样本数。数据信息如该区域的繁华程度、教育资源、治安等情况就和预测的房价比较相关,有代表性。而诸如该区域“人均养的兔子数”类数据信息,对房价的预测就没那么相关,对于无代表性的数据特征的加入,主要会增加人工处理的成本、计算复杂度,还有可能引入了模型学习的噪音。\r\n\r\n- 划定好数据时间窗口。比如我们可以学习该区域历史2010~2020年的房价,预测未来2021的房价(这是一个经典的时间序列预测问题,常用RNN模型)。但却不能学习了2021年或者更后面的未来房价、人口数等相关信息,反过来去预测2021年房价,这就是一个数据泄露的问题(模型都学习了与标签相关等未知的信息,还预测个啥?)。\r\n\r\n#### 本节代码\r\n如下加载数据的代码,使用的是keras自带的波士顿房价数据集。一些常用的机器学习开源数据集可以到kaggle.com/datasets、archive.ics.uci.edu等网站下载。\r\n\r\n\r\n```\r\nfrom keras.datasets import boston_housing #导入波士顿房价数据集\r\n\r\n(train_x, train_y), (test_x, test_y) = boston_housing.load_data()\r\n```\r\n波士顿房价数据集是统计20世纪70年代中期波士顿郊区房价等情况,有当时城镇的犯罪率、房产税等共计13个指标(特征)以及对应的房价中位数(标签)。\r\n\r\n\r\n\r\n### 2.2 特征工程\r\n特征工程就是对原始数据分析处理,转化为模型可用的特征。这些特征可以更好地向预测模型描述潜在规律,从而提高模型对未见数据的准确性。对于深度学习模型,特征生成等加工不多,主要是一些数据的分析、预处理,然后就可以灌入神经网络模型了。\r\n\r\n#### 2.2.1 探索性数据分析\r\n选择好数据后,可以先做探索性数据分析(EDA)去理解数据本身的内部结构及规律。如果你对数据情况不了解,也没有相关的业务背景知识,不做相关的分析及预处理,直接将数据喂给模型往往效果不太好。通过探索性数据分析,可以了解数据分布、缺失、异常及相关性等情况。\r\n#### 本节代码\r\n我们可以通过EDA数据分析库如pandas profiling,自动生成分析报告,可以看到这份现成的数据集是比较\"干净的\":\r\n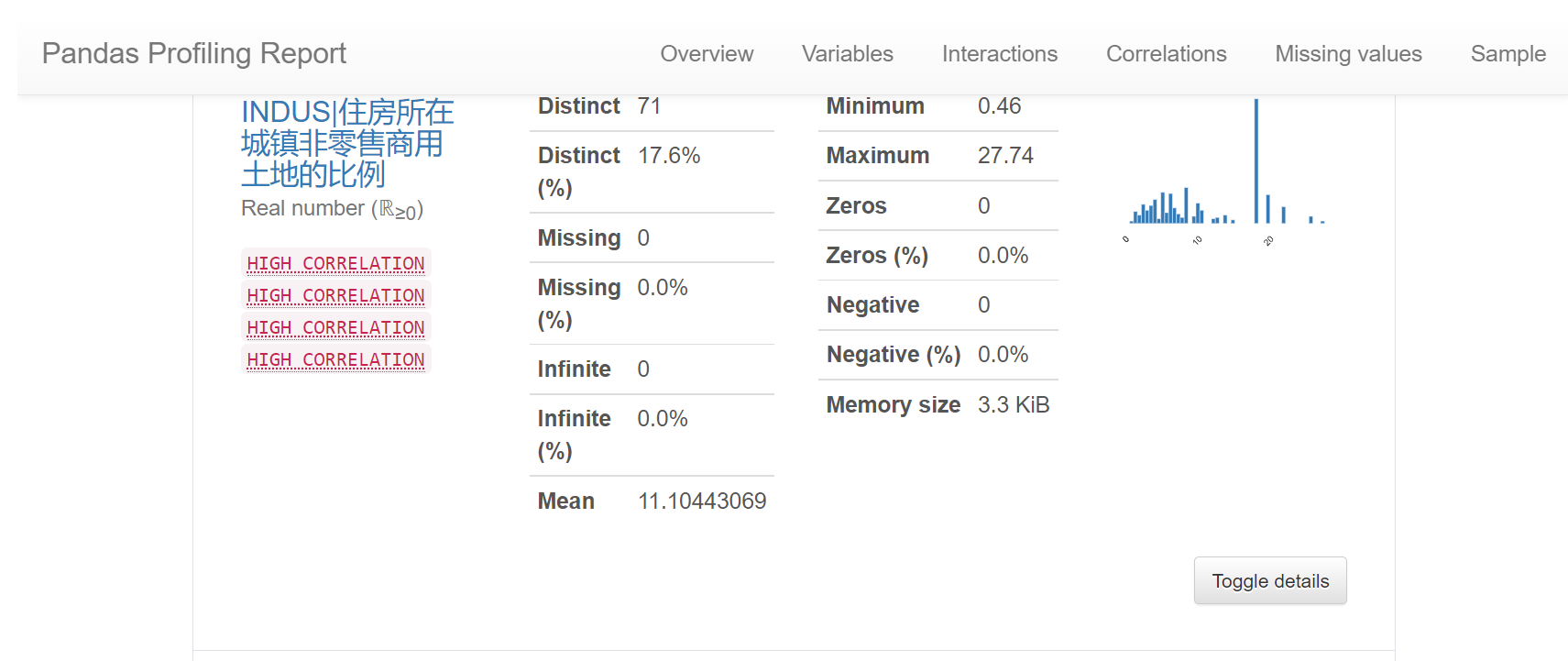\r\n```\r\nimport pandas as pd \r\nimport pandas_profiling\r\n\r\n# 特征名称\r\nfeature_name = ['CRIM|住房所在城镇的人均犯罪率',\r\n 'ZN|住房用地超过 25000 平方尺的比例',\r\n 'INDUS|住房所在城镇非零售商用土地的比例',\r\n 'CHAS|有关查理斯河的虚拟变量(如果住房位于河边则为1,否则为0 )',\r\n 'NOX|一氧化氮浓度',\r\n 'RM|每处住房的平均房间数',\r\n 'AGE|建于 1940 年之前的业主自住房比例',\r\n 'DIS|住房距离波士顿五大中心区域的加权距离',\r\n 'RAD|距离住房最近的公路入口编号',\r\n 'TAX 每 10000 美元的全额财产税金额',\r\n 'PTRATIO|住房所在城镇的师生比例',\r\n 'B|1000(Bk|0.63)^2,其中 Bk 指代城镇中黑人的比例',\r\n 'LSTAT|弱势群体人口所占比例']\r\n\r\ntrain_df = pd.DataFrame(train_x, columns=feature_name) # 转为df格式\r\n\r\npandas_profiling.ProfileReport(train_df) \r\n```\r\n#### 2.2.2 特征表示\r\n像图像、文本字符类的数据,需要转换为计算机能够处理的数值形式。图像数据(pixel image)实际上是由一个像素组成的矩阵所构成的,而每一个像素点又是由RGB颜色通道中分别代表R、G、B的一个三维向量表示,所以图像实际上可以用RGB三维矩阵(3-channel matrix)的表示(第一个维度:高度,第二个维度:宽度,第三个维度:RGB通道),最终再重塑为一列向量(reshaped image vector)方便输入模型。\r\n\r\n\r\n\r\n文本类(类别型)的数据可以用多维数组表示,包括:\r\n① ONEHOT(独热编码)表示:它是用单独一个位置的0或1来表示每个变量值,这样就可以将每个不同的字符取值用唯一的多维数组来表示,将文字转化为数值。如字符类的性别信息就可以转换为“是否为男”、“是否为女”、“未知”等特征。\r\n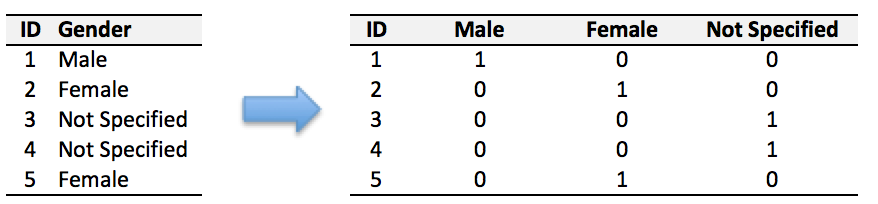\r\n\r\n②word2vetor分布式表示:它基本的思想是通过神经网络模型学习每个单词与邻近词的关系,从而将单词表示成低维稠密向量。通过这样的分布式表示可以学习到单词的语义信息,直观来看语义相似的单词其对应的向量距离相近。\r\n\r\n\r\n#### 本节代码\r\n数据集已是数值类数据,本节不做处理。\r\n\r\n#### 2.2.2 特征清洗\r\n- 异常值处理\r\n收集的数据由于人为或者自然因素可能引入了异常值(噪音),这会对模型学习进行干扰。 通常需要处理人为引起的异常值,通过业务及技术手段(如数据分布、3σ准则)判定异常值,再结合实际业务含义删除或者替换掉异常值。\r\n\r\n- 缺失值处理\r\n神经网络模型缺失值的处理是必要的,数据缺失值可以通过结合业务进行填充数值或者删除。\r\n① 缺失率较高,结合业务可以直接删除该特征变量。经验上可以新增一个bool类型的变量特征记录该字段的缺失情况,缺失记为1,非缺失记为0;\r\n② 缺失率较低,可使用一些缺失值填充手段,如结合业务fillna为0或-9999或平均值,或者训练回归模型预测缺失值并填充。\r\n\r\n#### 本节代码\r\n从数据分析报告可见,波士顿房价数据集无异常、缺失值情况,本节不做处理。\r\n\r\n\r\n#### 2.2.3 特征生成\r\n特征生成作用在于弥补基础特征对样本信息的表达有限,增加特征的非线性表达能力,提升模型效果。它是根据基础特征的含义进行某种处理(聚合 / 转换之类),常用方法如人工设计、自动化特征衍生(如featuretools工具):\r\n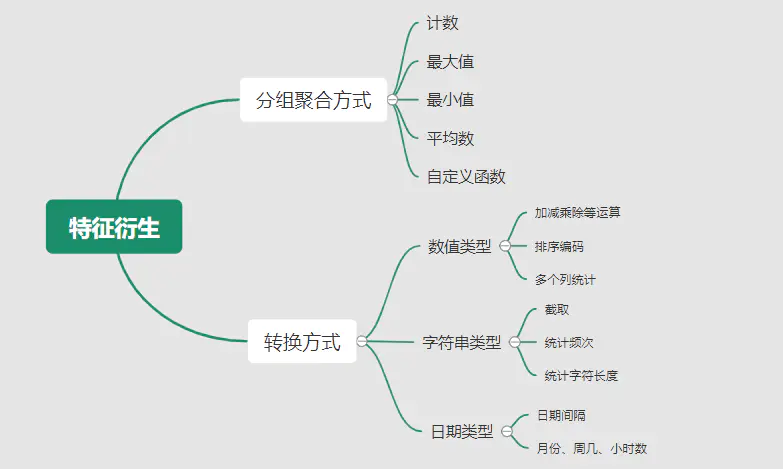\r\n深度神经网络会自动学习到高层次特征,常见的深度学习的任务,图像类、文本类任务通常很少再做特征生成。而对于数值类的任务,加工出显著特征对加速模型的学习是有帮助的,可以做尝试。具体可见系列文章:[一文归纳Python特征生成方法(全)](https://mp.weixin.qq.com/s/MkXOE1VrZz2IWBvvHC06bA)\r\n\r\n#### 本节代码\r\n特征已经比较全面,本节不再做处理,可自行验证特征生成的效果。\r\n\r\n#### 2.2.4 特征选择\r\n特征选择用于筛选出显著特征、摒弃非显著特征。这样做主要可以减少特征(避免维度灾难),提高训练速度,降低运算开销;减少干扰噪声,降低过拟合风险,提升模型效果。常用的特征选择方法有:过滤法(如特征缺失率、单值率、相关系数)、包装法(如RFE递归特征消除、双向搜索)、嵌入法(如带L1正则项的模型、树模型自带特征选择)。具体可见系列文章:[Python特征选择(全)](https://mp.weixin.qq.com/s/YWqaza96XsNehkJCN-lWMg)\r\n#### 本节代码\r\n模型使用L1正则项方法,本节不再做处理,可自行验证其他方法。\r\n\r\n### 2.3 模型训练\r\n神经网络模型的训练主要有3个步骤:\r\n- 构建模型结构(主要有神经网络结构设计、激活函数的选择、模型权重如何初始化、网络层是否批标准化、正则化策略的设定)\r\n- 模型编译(主要有学习目标、优化算法的设定)\r\n- 模型训练及超参数调试(主要有划分数据集,超参数调节及训练)\r\n#### 2.3.1 模型结构\r\n常见的神经网络模型结构有全连接神经网络(FCN)、RNN(常用于文本 / 时间系列任务)、CNN(常用于图像任务)等等。具体可以看之前文章:[一文概览神经网络模型](https://mp.weixin.qq.com/s/ovx_lj2rCrrTx8DeU03yjQ)\r\n\r\n神经网络由输入层、隐藏层与输出层构成。不同的层数、神经元(计算单元)数目的模型性能也会有差异。\r\n\r\n- 输入层:为数据特征输入层,输入数据特征维数就对应着网络的神经元数。(注:输入层不计入模型层数)\r\n- 隐藏层:即网络的中间层(可以很多层),其作用接受前一层网络输出作为当前的输入值,并计算输出当前结果到下一层。隐藏层的层数及神经元个数直接影响模型的拟合能力。\r\n- 输出层:为最终结果输出的网络层。输出层的神经元个数代表了分类类别的个数(注:在做二分类时情况特殊一点,如果输出层的激活函数采用sigmoid,输出层的神经元个数为1个;如果采用softmax,输出层神经元个数为2个是与分类类别个数对应的;)\r\n\r\n\r\n对于模型结构的神经元个数 ,输入层、输出层的神经元个数通常是确定的,主要需要考虑的是隐藏层的深度及宽度,在忽略网络退化问题的前提下,通常隐藏层的神经元的越多,模型有更多的容量(capcity)去达到更好的拟合效果(也更容易过拟合)。搜索合适的网络深度及宽度,常用有人工经验调参、随机 / 网格搜索、贝叶斯优化等方法。经验上的做法,可以参照下同类任务效果良好的神经网络模型的结构,结合实际的任务,再做些微调。\r\n\r\n#### 2.3.2 激活函数\r\n根据万能近似原理,简单来说,神经网络有“够深的网络层”以及“至少一层带激活函数的隐藏层”,既可以拟合任意的函数。可见激活函数的重要性,它起着特征空间的非线性转换。对于激活函数选择的经验性做法:\r\n- 对于输出层,二分类的输出层的激活函数常选择sigmoid函数,多分类选择softmax;回归任务根据输出值范围来确定使不使用激活函数。\r\n- 对于隐藏层的激活函数通常会选择使用ReLU函数,保证学习效率。\r\n具体可见序列文章:[一文讲透神经网络的激活函数](https://mp.weixin.qq.com/s/vvhMkwT6uSVBaqzd6urMqw)\r\n\r\n#### 2.3.3 权重初始化\r\n权重参数初始化可以加速模型收敛速度,影响模型结果。常用的初始化方法有:\r\n- uniform均匀分布初始化\r\n- normal高斯分布初始化\r\n需要注意的是,权重不能初始化为0,这会导致多个隐藏神经元的作用等同于1个神经元,无法收敛。\r\n\r\n#### 2.3.4 批标准化\r\nbatch normalization(BN)批标准化,是神经网络模型常用的一种优化方法。它的原理很简单,即是对原来的数值进行标准化处理:\r\n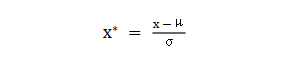\r\nbatch normalization在保留输入信息的同时,消除了层与层间的分布差异,具有加快收敛,同时有类似引入噪声正则化的效果。它可应用于网络的输入层或隐藏层,当用于输入层,就是线性模型常用的特征标准化处理。\r\n\r\n#### 2.3.5 正则化\r\n正则化是在以(可能)增加经验损失为代价,以降低泛化误差为目的,抑制过拟合,提高模型泛化能力的方法。经验上,对于复杂任务,深度学习模型偏好带有正则化的较复杂模型,以达到较好的学习效果。常见的正则化策略有:dropout,L1、L2、earlystop方法。具体可见序列文章:[一文深层解决模型过拟合](https://mp.weixin.qq.com/s/TOwUmN3TTW93o1xSYNb_Aw)\r\n\r\n\r\n\r\n#### 2.3.6 选择学习目标\r\n机器 / 深度学习通过学习到“好”的模型去决策,“好”即是机器 / 深度学习的学习目标,通常也就是预测值与目标值之间的误差尽可能的低。衡量这种误差的函数称为代价函数 (Cost Function)或者损失函数(Loss Function),更具体地说,机器 / 深度学习的目标是极大化降低损失函数。\r\n\r\n对于不同的任务,往往也需要用不同损失函数衡量,经典的损失函数包括回归任务的均方误差损失函数及二分类任务的交叉熵损失函数等。\r\n- 均方误差损失函数\r\n\r\n衡量模型回归预测的误差情况,一个简单思路是用各个样本i的预测值f(x;w)减去实际值y求平方后的平均值,这也就是经典的均方误差(Mean Squared Error)损失函数。通过极小化降低均方误差损失函数,可以使得模型预测值与实际值数值差异尽量小。\r\n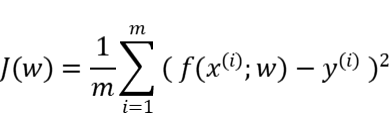\r\n\r\n- 交叉熵损失函数\r\n\r\n衡量二分类预测模型的误差情况,常用交叉熵损失函数,使得模型预测分布尽可能与实际数据经验分布一致(最大似然估计)。\r\n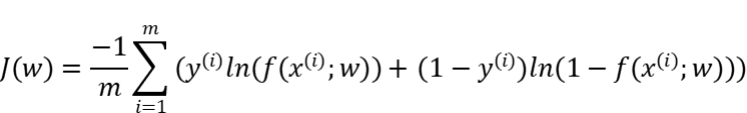\r\n另外,还有一些针对优化难点而设计的损失函数,如Huber Loss主要用于解决回归问题中,存在奇点数据带偏模型训练的问题。Focal Loss主要解决分类问题中类别不均衡导致的模型训偏问题。\r\n\r\n#### 2.3.7 选择优化算法\r\n当我们机器 / 深度学习的学习目标是极大化降低(某个)损失函数,那么如何实现这个目标呢?通常机器学习模型的损失函数较复杂,很难直接求损失函数最小的公式解。幸运的是,我们可以通过优化算法(如梯度下降、随机梯度下降、Adam等)有限次迭代优化模型参数,以尽可能降低损失函数的值,得到较优的参数值。具体可见系列文章:[一文概览神经网络优化算法](https://mp.weixin.qq.com/s/JZ2SpbDI75GvZD9C2DSikA)\r\n\r\n\r\n对于大多数任务而言,通常可以直接先试下Adam、SGD,然后可以继续在具体任务上验证不同优化器效果。\r\n\r\n\r\n### 2.3.8 模型训练及超参数调试\r\n- 划分数据集\r\n\r\n训练模型前,常用的HoldOut验证法(此外还有留一法、k折交叉验证等方法),把数据集分为训练集和测试集,并可再对训练集进一步细分为训练集和验证集,以方便评估模型的性能。\r\n① 训练集(training set):用于运行学习算法,训练模型。\r\n② 开发验证集(development set)用于调整模型超参数、EarlyStopping、选择特征等,以选择出合适模型。\r\n③ 测试集(test set)只用于评估已选择模型的性能,但不会据此改变学习算法或参数。\r\n\r\n- 超参数调试\r\n\r\n神经网络模型的超参数是比较多的:数据方面超参数 如验证集比例、batch size等;模型方面 如单层神经元数、网络深度、选择激活函数类型、dropout率等;学习目标方面 如选择损失函数类型,正则项惩罚系数等;优化算法方面 如选择梯度算法类型、初始学习率等。\r\n\r\n常用的超参调试有人工经验调节、网格搜索(grid search或for循环实现)、随机搜索(random search)、贝叶斯优化(bayesian optimization)等方法,方法介绍可见系列文章:[一文归纳Ai调参炼丹之法](https://mp.weixin.qq.com/s/f4-f6CDTMn5o1MHqTQ6TXw)。\r\n\r\n另外,有像Keras Tuner分布式超参数调试框架(文档见:keras.io/keras_tuner),集成了常用调参方法,还比较实用的。\r\n\r\n#### 本节代码\r\n- 创建模型结构\r\n结合当前房价预测任务是一个经典简单表格数据的回归预测任务。我们采用基础的全连接神经网络,隐藏层的深度一两层也就差不多。通过keras.Sequential方法来创建一个神经网络模型,并在依次添加带有批标准化的输入层,一层带有relu激活函数的k个神经元的隐藏层,并对这层隐藏层添加dropout、L1、L2正则的功能。由于回归预测数值实际范围(5~50+)直接用线性输出层,不需要加激活函数。\r\n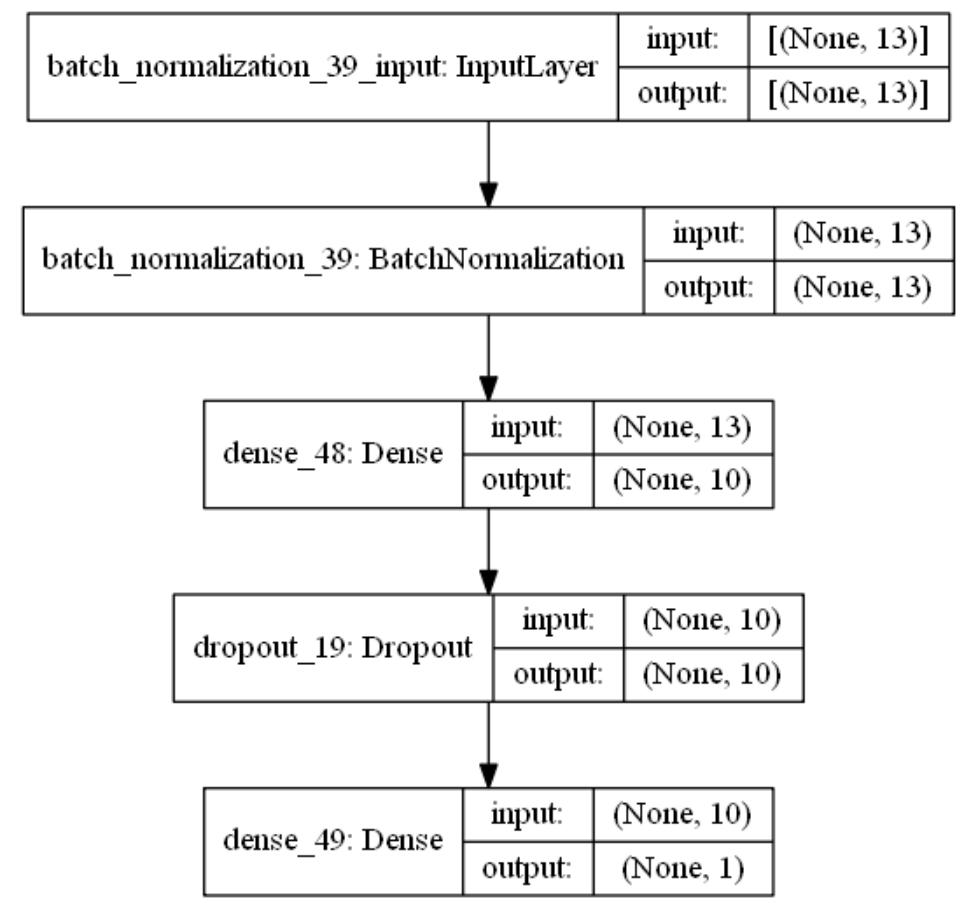\r\n```\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\n%matplotlib inline\r\nfrom tensorflow import random\r\nfrom keras import regularizers\r\nfrom keras.layers import Dense,Dropout,BatchNormalization\r\nfrom keras.models import Sequential, Model\r\nfrom keras.callbacks import EarlyStopping\r\nfrom sklearn.metrics import mean_squared_error\r\n\r\nnp.random.seed(1) # 固定随机种子,使每次运行结果固定\r\nrandom.set_seed(1)\r\n\r\n\r\n# 创建模型结构:输入层的特征维数为13;1层k个神经元的relu隐藏层;线性的输出层;\r\n\r\nfor k in [5,20,50]: # 网格搜索超参数:神经元数k\r\n \r\n model = Sequential()\r\n\r\n model.add(BatchNormalization(input_dim=13)) # 输入层 批标准化 \r\n\r\n model.add(Dense(k, \r\n kernel_initializer='random_uniform', # 均匀初始化\r\n activation='relu', # relu激活函数\r\n kernel_regularizer=regularizers.l1_l2(l1=0.01, l2=0.01), # L1及L2 正则项\r\n use_bias=True)) # 隐藏层\r\n\r\n model.add(Dropout(0.1)) # dropout法\r\n\r\n model.add(Dense(1,use_bias=True)) # 输出层\r\n \r\n```\r\n- 模型编译\r\n设定学习目标为(最小化)回归预测损失mse,优化算法为adam\r\n```\r\n model.compile(optimizer='adam', loss='mse') \r\n```\r\n- 模型训练\r\n我们通过传入训练集x,训练集标签y,使用fit(拟合)方法来训练模型,其中epochs为迭代次数,并通过EarlyStopping及时停止在合适的epoch,减少过拟合;batch_size为每次epoch随机采样的训练样本数目。\r\n```\r\n# 训练模型\r\n history = model.fit(train_x, \r\n train_y, \r\n epochs=500, # 训练迭代次数\r\n batch_size=50, # 每epoch采样的batch大小\r\n validation_split=0.1, # 从训练集再拆分验证集,作为早停的衡量指标\r\n callbacks=[EarlyStopping(monitor='val_loss', patience=20)], #早停法\r\n verbose=False) # 不输出过程 \r\n\r\n \r\n print(\"验证集最优结果:\",min(history.history['val_loss']))\r\n model.summary() #打印模型概述信息\r\n # 模型评估:拟合效果\r\n plt.plot(history.history['loss'],c='blue') # 蓝色线训练集损失\r\n plt.plot(history.history['val_loss'],c='red') # 红色线验证集损失\r\n plt.show()\r\n```\r\n最后,这里简单采用for循环,实现类似网格搜索调整超参数,验证了隐藏层的不同神经元数目(超参数k)的效果。由验证结果来看,神经元数目为50时,损失可以达到10的较优效果(可以继续尝试模型增加深度、宽度,达到过拟合的边界应该有更好的效果)。\r\n\r\n\r\n\r\n注:本节使用的优化方法较多(炫技ing),单纯是为展示一遍各种深度学习的优化tricks。模型并不是优化方法越多越好,效果还是要实际问题具体验证。\r\n\r\n### 2.4 模型评估及优化\r\n机器学习学习的目标是极大化降低损失函数,但这不仅仅是学习过程中对训练数据有良好的预测能力(极低的训练损失),根本上还在于要对新数据(测试集)能有很好的预测能力(泛化能力)。\r\n\r\n- 评估模型误差的指标\r\n\r\n评估模型的预测误差常用损失函数的大小来判断,如回归预测的均方损失。但除此之外,对于一些任务,用损失函数作为评估指标并不直观,所以像分类任务的评估还常用f1-score,可以直接展现各种类别正确分类情况。\r\n\u003e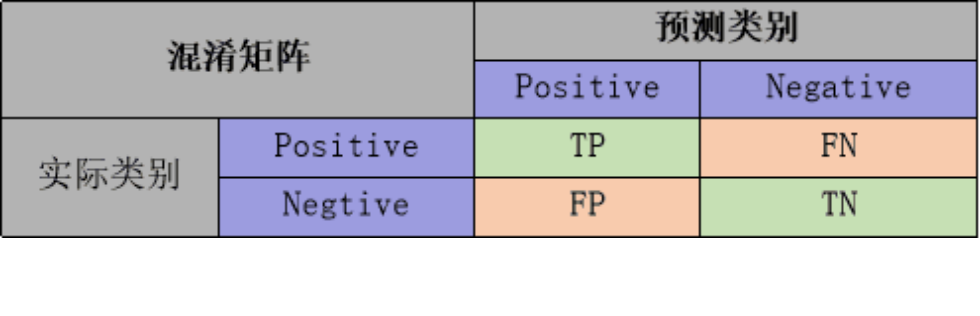查准率P:是指分类器预测为Positive的正确样本(TP)的个数占所有预测为Positive样本个数(TP+FP)的比例;\r\n查全率R:是指分类器预测为Positive的正确样本(TP)的个数占所有的实际为Positive样本个数(TP+FN)的比例。\r\nF1-score是查准率P、查全率R的调和平均:\r\n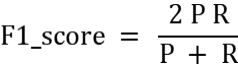\r\n\r\n注:如分类任务的f1-score等指标只能用于评估模型最终效果,因为作为学习目标时它们无法被高效地优化,训练优化时常用交叉熵作为其替代的分类损失函数 (surrogate loss function)。\r\n\r\n- 评估拟合效果\r\n\r\n评估模型拟合(学习)效果,常用欠拟合、拟合良好、过拟合来表述,通常,拟合良好的模型有更好泛化能力,在未知数据(测试集)有更好的效果。\r\n\r\n我们可以通过训练误差及验证集误差评估模型的拟合程度。从整体训练过程来看,欠拟合时训练误差和验证集误差均较高,随着训练时间及模型复杂度的增加而下降。在到达一个拟合最优的临界点之后,训练误差下降,验证集误差上升,这个时候模型就进入了过拟合区域。\r\n\r\n\r\n- 优化拟合效果的方法\r\n\r\n实践中通常欠拟合不是问题,可以通过使用强特征及较复杂的模型提高学习的准确度。而解决过拟合,即如何减少泛化误差,提高泛化能力,通常才是优化模型效果的重点,常用的方法在于提高数据的质量、数量以及采用适当的正则化策略。具体可见系列文章:[一文深层解决模型过拟合](https://mp.weixin.qq.com/s/TOwUmN3TTW93o1xSYNb_Aw)\r\n\r\n\r\n\r\n\r\n#### 本节代码\r\n```\r\n# 模型评估:拟合效果\r\nimport matplotlib.pyplot as plt\r\n\r\nplt.plot(history.history['loss'],c='blue') # 蓝色线训练集损失\r\nplt.plot(history.history['val_loss'],c='red') # 红色线验证集损失\r\n```\r\n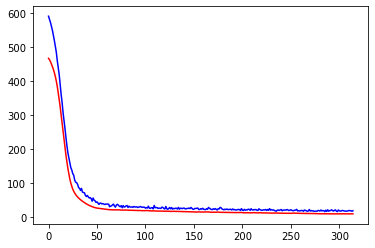\r\n从训练集及验证集的损失来看,训练集、验证集损失都比较低,模型没有过拟合现象。\r\n\r\n\r\n```\r\n# 模型评估:测试集预测结果\r\npred_y = model.predict(test_x)[:,0]\r\n\r\nprint(\"正确标签:\",test_y)\r\nprint(\"模型预测:\",pred_y )\r\n\r\nprint(\"实际与预测值的差异:\",mean_squared_error(test_y,pred_y ))\r\n\r\n#绘图表示\r\nimport matplotlib.pyplot as plt\r\n\r\nplt.rcParams['font.sans-serif'] = ['SimHei']\r\nplt.rcParams['axes.unicode_minus'] = False\r\n\r\n# 设置图形大小\r\nplt.figure(figsize=(8, 4), dpi=80)\r\nplt.plot(range(len(test_y)), test_y, ls='-.',lw=2,c='r',label='真实值')\r\nplt.plot(range(len(pred_y)), pred_y, ls='-',lw=2,c='b',label='预测值')\r\n\r\n# 绘制网格\r\nplt.grid(alpha=0.4, linestyle=':')\r\nplt.legend()\r\nplt.xlabel('number') #设置x轴的标签文本\r\nplt.ylabel('房价') #设置y轴的标签文本\r\n\r\n# 展示\r\nplt.show()\r\n```\r\n\r\n\r\n评估测试集的预测结果,其mse损失为19.7,观察测试集的实际值与预测值两者的数值曲线是比较一致的!模型预测效果较好。\r\n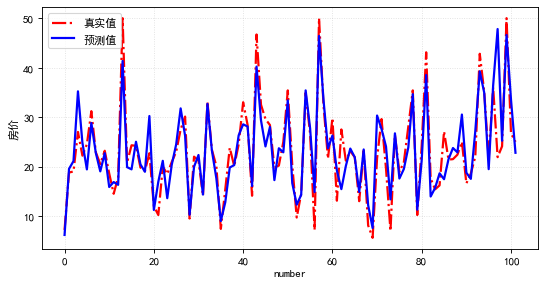\r\n\r\n\r\n### 2.5 模型预测结果及解释性\r\n决策应用是机器学习最终目的,对模型预测信息加以分析解释,并应用于实际的工作领域。\r\n\r\n对于实际工作需要注意的是,工程上是结果导向,模型在线上运行的效果直接决定模型的成败,不仅仅包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性的综合考虑。\r\n\r\n对于神经网络模型预测的分析解释,我们有时需要知道学习的内容,决策的过程是怎么样的(模型的可解释性)。具体可见系列文章:[神经网络学习到的是什么?](https://mp.weixin.qq.com/s/17NnbTuCEvK0ZnQ_1OCZQQ)一个可以解释的AI模型(Explainable AI, 简称XAI)意味着运作的透明,便于人类对于对AI决策的监督及接纳,以保证算法的公平性、安全性及隐私性,从而创造更加安全可靠的应用。深度学习可解释性常用方法有:LIME、LRP、SHAP等方法。\r\n\r\n#### 本节代码\r\n如下通过SHAP方法,对模型预测单个样本的结果做出解释,可见在这个样本的预测中,CRIM犯罪率为0.006、RM平均房间数为6.575对于房价是负相关的。LSTAT弱势群体人口所占比例为4.98对于房价的贡献是正相关的...,在综合这些因素后模型给出最终预测值。\r\n```\r\nimport shap \r\nimport tensorflow as tf # tf版本\u003c2.0\r\n\r\n# 模型解释性\r\nbackground = test_x[np.random.choice(test_x.shape[0],100, replace=False)]\r\nexplainer = shap.DeepExplainer(model,background)\r\nshap_values = explainer.shap_values(test_x) # 传入特征矩阵X,计算SHAP值\r\n# 可视化第一个样本预测的解释 \r\nshap.force_plot(explainer.expected_value, shap_values[0,:], test_x.iloc[0,:])\r\n```\r\n\r\n\r\n\r\n\r\n\r\n(END)\r\n--- \r\n文章首发公众号“算法进阶”,阅读原文可访问[文章相关代码及资料](https://github.com/aialgorithm/Blog)","author":{"url":"https://github.com/aialgorithm","@type":"Person","name":"aialgorithm"},"datePublished":"2021-11-13T04:19:19.000Z","interactionStatistic":{"@type":"InteractionCounter","interactionType":"https://schema.org/CommentAction","userInteractionCount":0},"url":"https://github.com/31/Blog/issues/31"}| route-pattern | /_view_fragments/issues/show/:user_id/:repository/:id/issue_layout(.:format) |
| route-controller | voltron_issues_fragments |
| route-action | issue_layout |
| fetch-nonce | v2:e50a5731-296f-d0f0-0bde-02366fe97b89 |
| current-catalog-service-hash | 81bb79d38c15960b92d99bca9288a9108c7a47b18f2423d0f6438c5b7bcd2114 |
| request-id | 8EA6:347527:CE8EE4:120E9DF:696A2236 |
| html-safe-nonce | ba926d234f65cc10bf0b5b4acf2d0f90073307eef05ad82995d9773b404a1f8f |
| visitor-payload | eyJyZWZlcnJlciI6IiIsInJlcXVlc3RfaWQiOiI4RUE2OjM0NzUyNzpDRThFRTQ6MTIwRTlERjo2OTZBMjIzNiIsInZpc2l0b3JfaWQiOiI4NDI2MDcxMzM1MDQ0MjYwNDA2IiwicmVnaW9uX2VkZ2UiOiJpYWQiLCJyZWdpb25fcmVuZGVyIjoiaWFkIn0= |
| visitor-hmac | 751496549476da9bb2e4768d1937e304a02a8338c7bf02884ac01320199f472c |
| hovercard-subject-tag | issue:1052539134 |
| github-keyboard-shortcuts | repository,issues,copilot |
| google-site-verification | Apib7-x98H0j5cPqHWwSMm6dNU4GmODRoqxLiDzdx9I |
| octolytics-url | https://collector.github.com/github/collect |
| analytics-location | / |
| fb:app_id | 1401488693436528 |
| apple-itunes-app | app-id=1477376905, app-argument=https://github.com/_view_fragments/issues/show/aialgorithm/Blog/31/issue_layout |
| twitter:image | https://opengraph.githubassets.com/a8736ad1b046970c16284ff84426a235e8783f92dfee590a797aa5656e8c78c0/aialgorithm/Blog/issues/31 |
| twitter:card | summary_large_image |
| og:image | https://opengraph.githubassets.com/a8736ad1b046970c16284ff84426a235e8783f92dfee590a797aa5656e8c78c0/aialgorithm/Blog/issues/31 |
| og:image:alt | 本文详细地梳理及实现了深度学习模型构建及预测的全流程,代码示例基于python及神经网络库keras,通过设计一个深度神经网络模型做波士顿房价预测。主要依赖的Python库有:keras、scikit-learn、pandas、tensorflow(建议可以安装下anaconda包,自带有常用的python库) 一、基础介绍 机器学习 机器学习的核心是通过模型从数据中学习并利用经验去决策。进... |
| og:image:width | 1200 |
| og:image:height | 600 |
| og:site_name | GitHub |
| og:type | object |
| og:author:username | aialgorithm |
| hostname | github.com |
| expected-hostname | github.com |
| None | 014f3d193f36b7d393f88ca22d06fbacd370800b40a547c1ea67291e02dc8ea3 |
| turbo-cache-control | no-preview |
| go-import | github.com/aialgorithm/Blog git https://github.com/aialgorithm/Blog.git |
| octolytics-dimension-user_id | 33707637 |
| octolytics-dimension-user_login | aialgorithm |
| octolytics-dimension-repository_id | 147093233 |
| octolytics-dimension-repository_nwo | aialgorithm/Blog |
| octolytics-dimension-repository_public | true |
| octolytics-dimension-repository_is_fork | false |
| octolytics-dimension-repository_network_root_id | 147093233 |
| octolytics-dimension-repository_network_root_nwo | aialgorithm/Blog |
| turbo-body-classes | logged-out env-production page-responsive |
| disable-turbo | false |
| browser-stats-url | https://api.github.com/_private/browser/stats |
| browser-errors-url | https://api.github.com/_private/browser/errors |
| release | d515f6f09fa57a93bf90355cb894eb84ca4f458f |
| ui-target | full |
| theme-color | #1e2327 |
| color-scheme | light dark |
Links:
Viewport: width=device-width