Title: 一文全览机器学习建模流程(Python代码) · Issue #21 · aialgorithm/Blog · GitHub
Open Graph Title: 一文全览机器学习建模流程(Python代码) · Issue #21 · aialgorithm/Blog
X Title: 一文全览机器学习建模流程(Python代码) · Issue #21 · aialgorithm/Blog
Description: 注:本文基于之前的文章做了些修改,重复部分可以跳过看。示例的项目为基于LR模型对癌细胞分类的任务。 随着人工智能时代的到来,机器学习已成为解决问题的关键工具。我们接下来会详细介绍机器学习如何应用到实际问题,并概括机器学习应用的一般流程。 1.1 明确问题 明确业务问题是机器学习的先决条件,即抽象出该问题为机器学习的预测问题:需要学习什么样的数据作为输入,目标是得到什么样的模型做决策作为输出。 一个简单的新闻分类的场景,就是学习已有的新闻及其类别标签数据,得到一个文本分类...
Open Graph Description: 注:本文基于之前的文章做了些修改,重复部分可以跳过看。示例的项目为基于LR模型对癌细胞分类的任务。 随着人工智能时代的到来,机器学习已成为解决问题的关键工具。我们接下来会详细介绍机器学习如何应用到实际问题,并概括机器学习应用的一般流程。 1.1 明确问题 明确业务问题是机器学习的先决条件,即抽象出该问题为机器学习的预测问题:需要学习什么样的数据作为输入,目标是得到什么样的模型做决策作为输出。...
X Description: 注:本文基于之前的文章做了些修改,重复部分可以跳过看。示例的项目为基于LR模型对癌细胞分类的任务。 随着人工智能时代的到来,机器学习已成为解决问题的关键工具。我们接下来会详细介绍机器学习如何应用到实际问题,并概括机器学习应用的一般流程。 1.1 明确问题 明确业务问题是机器学习的先决条件,即抽象出该问题为机器学习的预测问题:需要学习什么样的数据作为输入,目标是得到什么样的模型做决策作为输出。...
Opengraph URL: https://github.com/aialgorithm/Blog/issues/21
X: @github
Domain: github.com
{"@context":"https://schema.org","@type":"DiscussionForumPosting","headline":"一文全览机器学习建模流程(Python代码)","articleBody":"\r\n\r\n\u003e 注:本文基于之前的文章做了些修改,重复部分可以跳过看。示例的项目为基于LR模型对癌细胞分类的任务。\r\n\r\n随着人工智能时代的到来,机器学习已成为解决问题的关键工具。我们接下来会详细介绍机器学习如何应用到实际问题,并概括机器学习应用的一般流程。\r\n\r\n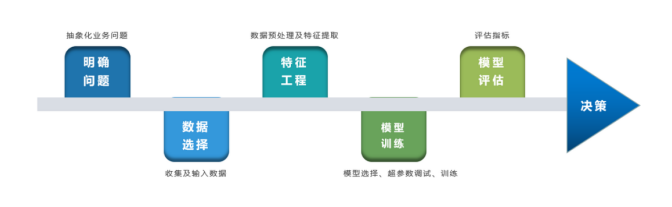\r\n\r\n\r\n## 1.1 明确问题\r\n明确业务问题是机器学习的先决条件,即抽象出该问题为机器学习的预测问题:需要学习什么样的数据作为输入,目标是得到什么样的模型做决策作为输出。\r\n一个简单的新闻分类的场景,就是学习已有的新闻及其类别标签数据,得到一个文本分类模型,通过模型对每天新的新闻做类别预测,以归类到每个新闻频道。\r\n\r\n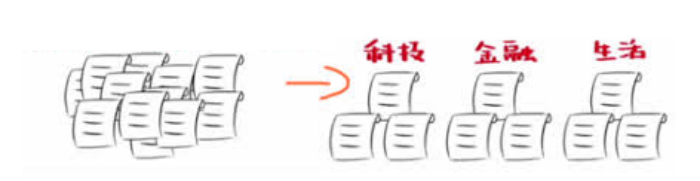\r\n\r\n## 1.2 数据选择\r\n机器学习广泛流传一句话:“数据和特征决定了机器学习结果的上限,而模型算法只是尽可能逼近这个上限”,意味着数据及其特征表示的质量决定了模型的最终效果,且在实际的工业应用中,算法通常占了很小的一部分,大部分的工作都是在找数据、提炼数据、分析数据及特征工程。\r\n\r\n数据选择是准备机器学习原料的关键,需要关注的是:\r\n① 数据的代表性:数据质量差或无代表性,会导致模型拟合效果差;\r\n② 数据时间范围:对于监督学习的特征变量X及标签Y,如与时间先后有关,则需要划定好数据时间窗口,否则可能会导致数据泄漏,即存在和利用因果颠倒的特征变量的现象。(如预测明天会不会下雨,但是训练数据引入明天温湿度情况); \r\n③ 数据业务范围:明确与任务相关的数据表范围,避免缺失代表性数据或引入大量无关数据作为噪音。\r\n\r\n## 2 特征工程\r\n特征工程就是对原始数据分析处理转化为模型可用的特征,这些特征可以更好地向预测模型描述潜在规律,从而提高模型对未见数据的准确性。特征工程按技术上可分为如下几步:\r\n① 探索性数据分析:数据分布、缺失、异常及相关性等情况;\r\n② 数据预处理:缺失值/异常值处理,数据离散化,数据标准化等;\r\n③ 特征提取:特征表示,特征衍生,特征选择,特征降维等;\r\n### 2.1 探索性数据分析\r\n拿到数据后,可以先做探索性数据分析(EDA)去理解数据本身的内部结构及规律,如果你对数据情况不了解也没有相关的业务背景知识,不做相关的分析及预处理,直接将数据喂给传统模型往往效果不太好。\r\n通过探索性数据分析,可以了解数据分布、缺失、异常及相关性等情况,利用这些基本信息做数据的处理及特征加工,可以进一步提高特征质量,灵活选择合适的模型方法。\r\n\r\n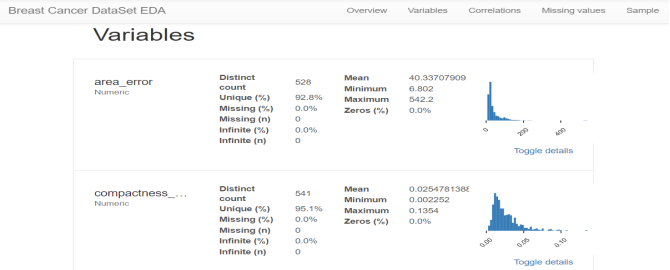\r\n\r\n### 2.2 数据预处理\r\n##### 异常值处理\r\n收集的数据由于人为或者自然因素可能引入了异常值(噪音),这会对模型学习进行干扰。 通常需要处理人为引起的异常值,通过业务或技术手段(如3σ准则)判定异常值,再由(正则式匹配)等方式筛选异常的信息,并结合业务情况删除或者替换数值。\r\n##### 缺失值处理\r\n数据缺失值可以通过结合业务进行填充数值、不做处理或者删除。根据特征缺失率情况及处理方式分为以下情况:\r\n ① 缺失率较高,并结合业务可以直接删除该特征变量。经验上可以新增一个bool类型的变量特征记录该字段的缺失情况,缺失记为1,非缺失记为0;\r\n ② 缺失率较低,结合业务可使用一些缺失值填充手段,如pandas的fillna方法、训练回归模型预测缺失值并填充;\r\n ③ 不做处理:部分模型如随机森林、xgboost、lightgbm能够处理数据缺失的情况,不需要对缺失数据再做处理。\r\n##### 数据离散化\r\n离散化是将连续的数据进行分段,使其变为一段段离散化的区间,分段的原则有等宽、等频等方法。通过离散化一般可以增加抗噪能力、使特征更有业务解释性、减小算法的时间及空间开销(不同算法情况不一)。\r\n##### 数据标准化\r\n数据各个特征变量的量纲差异很大,可以使用数据标准化消除不同分量量纲差异的影响,加速模型收敛的效率。常用的方法有:\r\n ① min-max 标准化:\r\n 可将数值范围缩放到(0, 1)且无改变数据分布。max为样本最大值,min为样本最小值。\r\n\r\n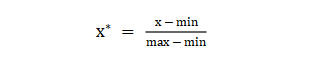\r\n\r\n ② z-score 标准化:\r\n 可将数值范围缩放到0附近, 经过处理的数据符合标准正态分布。是平均值,σ是标准差。\r\n\r\n \r\n\r\n### 2.3 特征提取\r\n##### 特征表示\r\n数据需要转换为计算机能够处理的数值形式,图片类的数据需要转换为RGB三维矩阵的表示。\r\n\r\n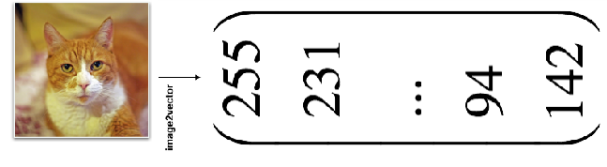\r\n\r\n字符类的数据可以用多维数组表示,有Onehot独热编码表示(用单独一个位置的1来表示)、word2vetor分布式表示等;\r\n\r\n\r\n\r\n##### 特征衍生\r\n基础特征对样本信息的表达有限,可通过特征衍生可以增加特征的非线性表达能力,提升模型效果。另外,在业务上的理解设计特征,还可以增加模型的可解释性。(如体重除以身高就是表达健康情况的重要特征。)\r\n特征衍生是对现有基础特征的含义进行某种处理(聚合/转换之类),常用方法人工设计、自动化特征衍生(图4.15):\r\n① 结合业务的理解做人工衍生设计:\r\n聚合的方式是指对字段聚合后求平均值、计数、最大值等。比如通过12个月工资可以加工出:平均月工资,薪资最大值 等等;\r\n转换的方式是指对字段间做加减乘除之类。比如通过12个月工资可以加工出:当月工资收入与支出的比值、差值等等;\r\n\r\n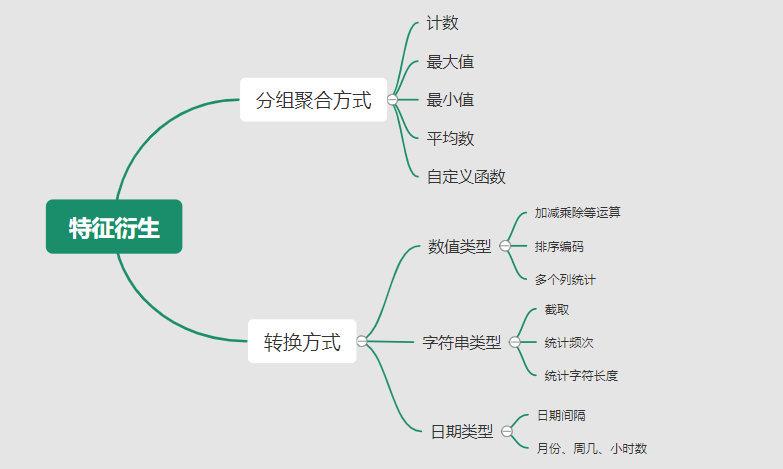\r\n\r\n② 使用自动化特征衍生工具:如Featuretools等,可以使用聚合(agg_primitives)、转换(trans_primitives)或则自定义方式暴力生成特征;\r\n##### 特征选择\r\n特征选择的目标是寻找最优特征子集,通过筛选出显著特征、摒弃冗余特征,减少模型的过拟合风险并提高运行效率。特征选择方法一般分为三类:\r\n① 过滤法:计算特征的缺失情况、发散性、相关性、信息量、稳定性等类型的指标对各个特征进行评估选择,常用如缺失率、单值率、方差验证、pearson相关系数、chi2卡方检验、IV值、信息增益及PSI等方法。\r\n② 包装法:通过每次选择部分特征迭代训练模型,根据模型预测效果评分选择特征的去留,如sklearn的RFE递归特征消除。\r\n③ 嵌入法:直接使用某些模型训练的到特征重要性,在模型训练同时进行特征选择。通过模型得到各个特征的权值系数,根据权值系数从大到小来选择特征。常用如基于L1正则项的逻辑回归、XGBOOST特征重要性选择特征。\r\n\r\n\r\n\r\n#### 特征降维\r\n如果特征选择后的特征数目仍太多,这种情形下常会有数据样本稀疏、距离计算困难的问题(称为 “维数灾难”),可以通过特征降维解决。常用的降维方法有:主成分分析法(PCA)等。\r\n## 3 模型训练\r\n模型训练是利用既定的模型方法去学习数据经验的过程,这过程还需要结合模型评估以调整算法的超参数,最终选择表现较优的模型。\r\n### 3.1 数据集划分\r\n训练模型前,常用的HoldOut验证法(此外还有留一法、k折交叉验证等方法),把数据集分为训练集和测试集,并可再对训练集进一步细分为训练集和验证集,以方便评估模型的性能。\r\n① 训练集(training set):用于运行学习算法,训练模型。\r\n② 开发验证集(development set)用于调整超参数、选择特征等,以选择合适模型。\r\n③ 测试集(test set)只用于评估已选择模型的性能,但不会据此改变学习算法或参数。\r\n###3.2 模型方法选择\r\n结合当前任务及数据情况选择合适的模型方法,常用的方法如下图 ,scikit-learn模型方法的选择。此外还可以结合多个模型做模型融合。\r\n\r\n\r\n\r\n### 3.3 训练过程\r\n模型的训练过程即学习数据经验得到较优模型及对应参数(如神经网络最终学习到较优的权重值)。整个训练过程还需要通过调节超参数(如神经网络层数、梯度下降的学习率)进行控制优化的。\r\n调节超参数是一个基于数据集、模型和训练过程细节的实证过程,需要基于对算法的原理理解和经验,借助模型在验证集的评估进行参数调优,此外还有自动调参技术:网格搜索、随机搜索及贝叶斯优化等。\r\n\r\n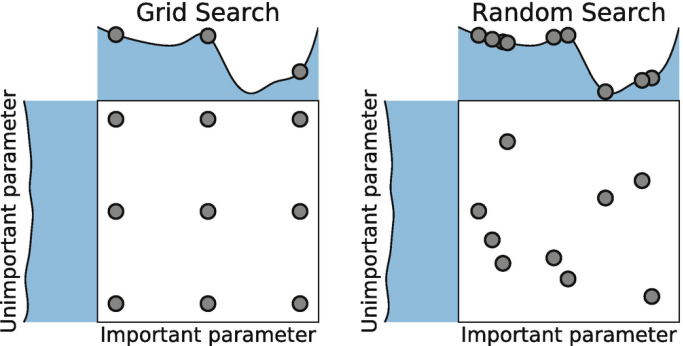\r\n\r\n## 4 模型评估\r\n机器学习的直接目的是学(拟合)到“好”的模型,不仅仅是学习过程中对训练数据的良好的学习预测能力,根本上在于要对新数据能有很好的预测能力(泛化能力),所以客观地评估模型性能至关重要。技术上常根据训练集及测试集的指标表现,评估模型的性能。\r\n### 4.1 评估指标\r\n##### 评估分类模型\r\n常用的评估标准有查准率P、查全率R及两者调和平均F1-score 等,并由混淆矩阵的统计相应的个数计算出数值:\r\n\r\n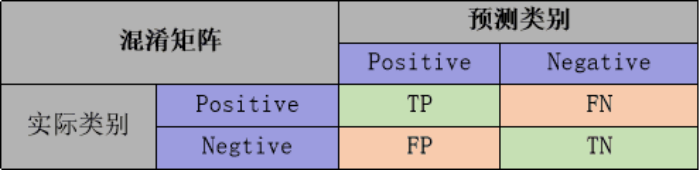\r\n\r\n查准率是指分类器分类正确的正样本(TP)的个数占该分类器所有预测为正样本个数(TP+FP)的比例;\r\n 查全率是指分类器分类正确的正样本个数(TP)占所有的正样本个数(TP+FN)的比例。\r\nF1-score是查准率P、查全率R的调和平均:\r\n\r\n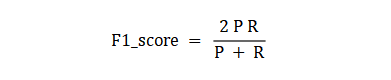\r\n\r\n##### 评估回归模型\r\n常用的评估指标有MSE均方误差等。反馈的是预测数值与实际值的拟合情况。\r\n\r\n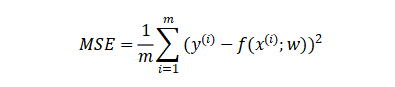\r\n\r\n##### 评估聚类模型\r\n可分为两类方式,一类将聚类结果与某个“参考模型”的结果进行比较,称为“外部指标”(external index):如兰德指数,FM指数等。另一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”(internal index):如紧凑度、分离度等。\r\n### 4.2 模型评估及优化\r\n训练机器学习模型所使用的数据样本集称之为训练集(training set), 在训练数据的误差称之为训练误差(training error),在测试数据上的误差,称之为测试误差(test error)或泛化误差 (generalization error)。\r\n\r\n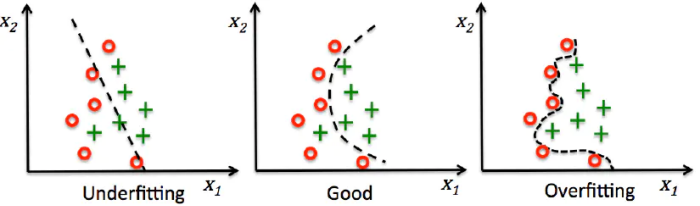\r\n\r\n描述模型拟合(学习)程度常用欠拟合、拟合良好、过拟合,我们可以通过训练误差及测试误差评估模型的拟合程度。从整体训练过程来看,欠拟合时训练误差和测试误差均较高,随着训练时间及模型复杂度的增加而下降。在到达一个拟合最优的临界点之后,训练误差下降,测试误差上升,这个时候就进入了过拟合区域。\r\n\r\n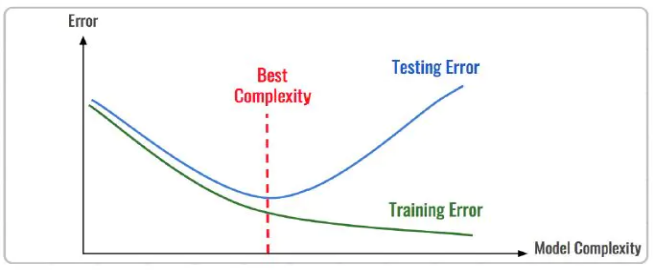\r\n\r\n欠拟合是指相较于数据而言模型结构过于简单,以至于无法学习到数据中的规律。\r\n过拟合是指模型只过分地匹配训练数据集,以至于对新数据无良好地拟合及预测。其本质是较复杂模型从训练数据中学习到了统计噪声导致的。\r\n分析模型拟合效果并对模型进行优化,常用的方法有:\r\n\r\n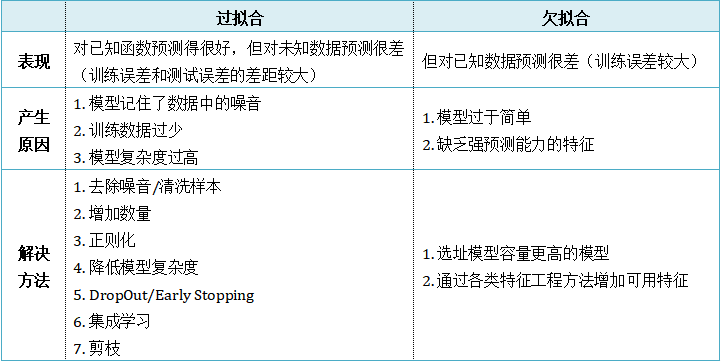\r\n\r\n## 5 模型决策\r\n决策应用是机器学习最终目的,对模型预测信息加以分析解释,并应用于实际的工作领域。需要注意的是,工程上是结果导向,模型在线上运行的效果直接决定模型的成败,不仅仅包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性的综合考虑。\r\n\r\n## 6 机器学习项目实战(数据挖掘)\r\n\r\n### 6.1 项目介绍\r\n\r\n项目的实验数据来源著名的UCI机器学习数据库,该数据库有大量的人工智能数据挖掘数据。本例选用的是sklearn上的数据集版本:Breast Cancer Wisconsin DataSet(威斯康星州乳腺癌数据集),这些数据来源美国威斯康星大学医院的临床病例报告,每条样本有30个特征属性,标签为是否良性肿瘤,即有监督分类预测的问题。 项目的建模思路是通过分析乳腺癌数据集数据,特征工程,构建逻辑回归模型学习数据,预测样本的类别是否为良性肿瘤。\r\n\r\n### 6.2 代码实现\r\n\r\n导入相关的Python库,加载cancer数据集,查看数据介绍, 并转为DataFrame格式。\r\n```\r\nimport numpy as np \r\nimport pandas as pd\r\nimport matplotlib.pyplot as plt\r\n\r\nfrom keras.models import Sequential\r\nfrom keras.layers import Dense, Dropout\r\nfrom keras.utils import plot_model\r\nfrom sklearn import datasets\r\nfrom sklearn.preprocessing import StandardScaler\r\nfrom sklearn.model_selection import train_test_split\r\nfrom sklearn.metrics import precision_score, recall_score, f1_score\r\n```\r\n```\r\ndataset_cancer = datasets.load_breast_cancer() # 加载癌细胞数据集\r\n\r\nprint(dataset_cancer['DESCR'])\r\n\r\ndf = pd.DataFrame(dataset_cancer.data, columns=dataset_cancer.feature_names) \r\n\r\ndf['label'] = dataset_cancer.target\r\n\r\nprint(df.shape)\r\n\r\ndf.head()\r\n```\r\n\r\n\r\n探索性数据分析EDA:使用pandas_profiling库分析数据数值情况,缺失率及相关性等。\r\n```\r\nimport pandas_profiling\r\n\r\npandas_profiling.ProfileReport(df, title='Breast Cancer DataSet EDA')\r\n```\r\n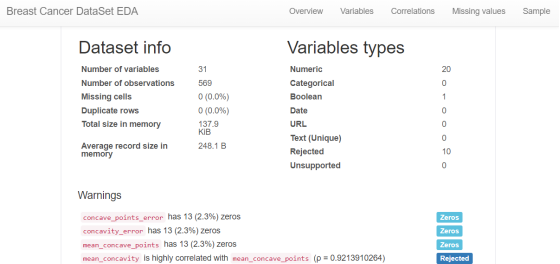\r\n\r\n特征工程方面主要的分析及处理有:\r\n● 分析特征无明显异常值及缺失的情况,无需处理;\r\n● 已有mean/standard error等衍生特征,无需特征衍生;\r\n● 结合相关性等指标做特征选择(过滤法);\r\n● 对特征进行标准化以加速模型学习过程;\r\n```\r\n# 筛选相关性\u003e0.99的特征清单列表及标签\r\ndrop_feas = ['label','worst_radius','mean_radius']\r\n\r\n# 选择标签y及特征x\r\ny = df.label\r\nx = df.drop(drop_feas,axis=1) # 删除相关性强特征及标签列\r\n\r\n# holdout验证法: 按3:7划分测试集 训练集\r\nx_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)\r\n\r\n# 特征z-score 标准化\r\nsc = StandardScaler()\r\n\r\nx_train = sc.fit_transform(x_train) # 注:训练集测试集要分别标准化,以免测试集信息泄露到模型训练\r\nx_test = sc.transform(x_test) \r\n```\r\n\r\n模型训练:使用keras搭建逻辑回归模型,训练模型,观察模型训练集及验证集的loss损失\r\n\r\n```\r\n_dim = x_train.shape[1] # 输入模型的特征数\r\n\r\n# LR逻辑回归模型\r\nmodel = Sequential() \r\n\r\nmodel.add(Dense(1, input_dim=_dim, activation='sigmoid',bias_initializer='uniform')) # 添加网络层,激活函数sigmoid\r\n\r\nmodel.summary()\r\n\r\nplot_model(model,show_shapes=True)\r\n```\r\n```\r\nmodel.compile(optimizer='adam', loss='binary_crossentropy') #模型编译:选择交叉熵损失函数及adam梯度下降法优化算法\r\n\r\nmodel.fit(x, y, validation_split=0.3, epochs=200) # 模型迭代训练: validation_split比例0.3, 迭代epochs200次\r\n\r\n# 模型训练集及验证集的损失\r\n\r\nplt.figure()\r\n\r\nplt.plot(model.history.history['loss'],'b',label='Training loss')\r\n\r\nplt.plot(model.history.history['val_loss'],'r',label='Validation val_loss')\r\n\r\nplt.title('Traing and Validation loss')\r\n\r\nplt.legend()\r\n```\r\n\r\n\r\n以测试集F1-score等指标的表现,评估模型的泛化能力。最终测试集的f1-score有88%,有较好的模型表现。\r\n\r\n\r\n```\r\ndef model_metrics(model, x, y):\r\n \"\"\"\r\n\r\n 评估指标\r\n\r\n \"\"\"\r\n yhat = model.predict(x).round() # 模型预测yhat,预测阈值按默认0.5划分\r\n\r\n result = {\r\n 'f1_score': f1_score(y, yhat),\r\n\r\n 'precision':precision_score(y, yhat),\r\n\r\n 'recall':recall_score(y, yhat)\r\n }\r\n\r\n return result\r\n\r\n# 模型评估结果\r\n\r\nprint(\"TRAIN\")\r\n\r\nprint(model_metrics(model, x_train, y_train))\r\n\r\nprint(\"TEST\")\r\n\r\nprint(model_metrics(model, x_test, y_test))\r\n```","author":{"url":"https://github.com/aialgorithm","@type":"Person","name":"aialgorithm"},"datePublished":"2021-08-19T08:39:49.000Z","interactionStatistic":{"@type":"InteractionCounter","interactionType":"https://schema.org/CommentAction","userInteractionCount":0},"url":"https://github.com/21/Blog/issues/21"}| route-pattern | /_view_fragments/issues/show/:user_id/:repository/:id/issue_layout(.:format) |
| route-controller | voltron_issues_fragments |
| route-action | issue_layout |
| fetch-nonce | v2:72ca0328-60f4-61e5-9e91-cd75f72342ca |
| current-catalog-service-hash | 81bb79d38c15960b92d99bca9288a9108c7a47b18f2423d0f6438c5b7bcd2114 |
| request-id | 83E6:333370:7D799F:ACD0FB:696A2279 |
| html-safe-nonce | 0ff2b25638f9375a38d503382b1d6a0cb16c34e1f5b2da8cc1a591f2ff779a40 |
| visitor-payload | eyJyZWZlcnJlciI6IiIsInJlcXVlc3RfaWQiOiI4M0U2OjMzMzM3MDo3RDc5OUY6QUNEMEZCOjY5NkEyMjc5IiwidmlzaXRvcl9pZCI6IjU4MzE5MTUyNTQzNzg1Mzc1OTMiLCJyZWdpb25fZWRnZSI6ImlhZCIsInJlZ2lvbl9yZW5kZXIiOiJpYWQifQ== |
| visitor-hmac | c95924bf5a4cc733ee79854c5b1b2145120ce822070a8c95b903e63ad9d0e029 |
| hovercard-subject-tag | issue:974418738 |
| github-keyboard-shortcuts | repository,issues,copilot |
| google-site-verification | Apib7-x98H0j5cPqHWwSMm6dNU4GmODRoqxLiDzdx9I |
| octolytics-url | https://collector.github.com/github/collect |
| analytics-location | / |
| fb:app_id | 1401488693436528 |
| apple-itunes-app | app-id=1477376905, app-argument=https://github.com/_view_fragments/issues/show/aialgorithm/Blog/21/issue_layout |
| twitter:image | https://opengraph.githubassets.com/0e706772323a4f9e2986efe2ebeb5fe4a488386d02c77be279c3dbe5a326a10d/aialgorithm/Blog/issues/21 |
| twitter:card | summary_large_image |
| og:image | https://opengraph.githubassets.com/0e706772323a4f9e2986efe2ebeb5fe4a488386d02c77be279c3dbe5a326a10d/aialgorithm/Blog/issues/21 |
| og:image:alt | 注:本文基于之前的文章做了些修改,重复部分可以跳过看。示例的项目为基于LR模型对癌细胞分类的任务。 随着人工智能时代的到来,机器学习已成为解决问题的关键工具。我们接下来会详细介绍机器学习如何应用到实际问题,并概括机器学习应用的一般流程。 1.1 明确问题 明确业务问题是机器学习的先决条件,即抽象出该问题为机器学习的预测问题:需要学习什么样的数据作为输入,目标是得到什么样的模型做决策作为输出。... |
| og:image:width | 1200 |
| og:image:height | 600 |
| og:site_name | GitHub |
| og:type | object |
| og:author:username | aialgorithm |
| hostname | github.com |
| expected-hostname | github.com |
| None | 014f3d193f36b7d393f88ca22d06fbacd370800b40a547c1ea67291e02dc8ea3 |
| turbo-cache-control | no-preview |
| go-import | github.com/aialgorithm/Blog git https://github.com/aialgorithm/Blog.git |
| octolytics-dimension-user_id | 33707637 |
| octolytics-dimension-user_login | aialgorithm |
| octolytics-dimension-repository_id | 147093233 |
| octolytics-dimension-repository_nwo | aialgorithm/Blog |
| octolytics-dimension-repository_public | true |
| octolytics-dimension-repository_is_fork | false |
| octolytics-dimension-repository_network_root_id | 147093233 |
| octolytics-dimension-repository_network_root_nwo | aialgorithm/Blog |
| turbo-body-classes | logged-out env-production page-responsive |
| disable-turbo | false |
| browser-stats-url | https://api.github.com/_private/browser/stats |
| browser-errors-url | https://api.github.com/_private/browser/errors |
| release | d515f6f09fa57a93bf90355cb894eb84ca4f458f |
| ui-target | full |
| theme-color | #1e2327 |
| color-scheme | light dark |
Links:
Viewport: width=device-width